
介绍Apache Spark® 4.1
内容提要
Spark 4.1增强了Spark Connect的稳定性和可扩展性,支持Python客户端的Spark ML,优化了模型缓存,提升机器学习性能。SQL功能扩展,支持复杂数据处理和递归CTE,新增VARIANT数据类型,提升读取性能,整体改善开发者体验,感谢社区贡献。
关键要点
-
Spark 4.1增强了Spark Connect的稳定性和可扩展性,支持Python客户端的Spark ML。
-
新增模型大小估算机制,优化模型缓存,提高机器学习性能。
-
引入Protobuf执行计划压缩和Arrow查询结果流式传输,提升大规模数据处理的稳定性。
-
SQL功能扩展,支持复杂数据处理和递归CTE,新增VARIANT数据类型。
-
VARIANT数据类型支持半结构化数据存储,性能提升显著。
-
引入递归公共表表达式,简化层次数据结构的处理。
-
感谢Apache Spark社区的贡献,推动了Spark 4.1的发布。
-
Spark 4.1是完全开源的,可以从spark.apache.org下载。
延伸解读
Spark Connect的稳定性提升
Spark 4.1在Spark Connect方面进行了显著改进,特别是在处理大规模和复杂工作负载时的稳定性和可扩展性。这些改进包括Protobuf执行计划的压缩和Arrow查询结果的流式传输,确保在高负载情况下的可靠性,适合需要高效数据处理的应用场景。
VARIANT数据类型的优势
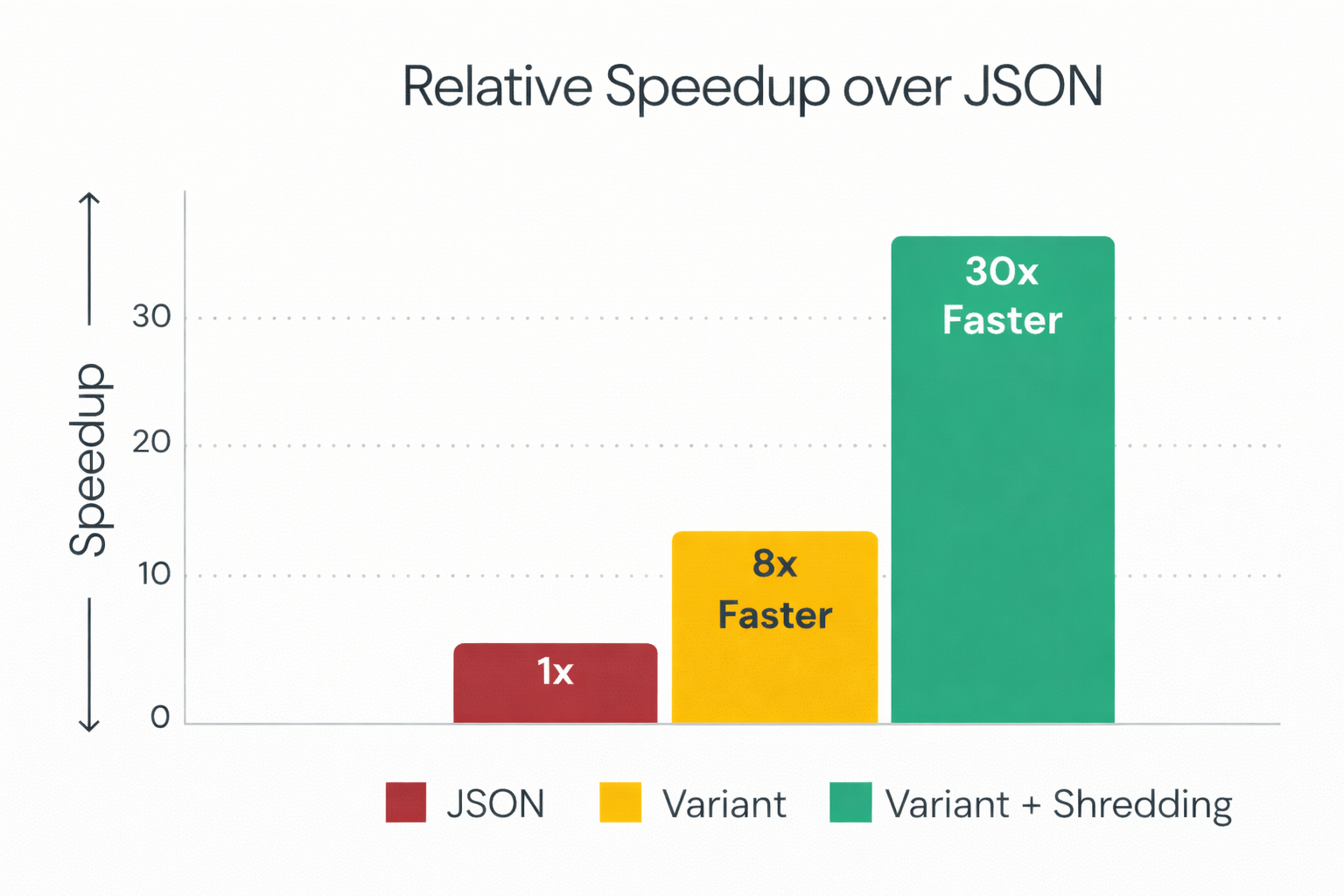
新引入的VARIANT数据类型为存储半结构化数据提供了标准化的方法,显著提升了读取性能。通过自动提取常见字段并将其存储为独立的Parquet字段,Spark 4.1在读取时可实现高达8倍的性能提升,适合需要频繁查询的分析任务。
SQL功能的扩展与应用
Spark 4.1扩展了SQL语言的功能,特别是递归公共表表达式的引入,使得处理层次数据结构变得更加简便。这一功能对于需要从传统系统迁移的用户尤为重要,能够简化数据处理流程,提高开发效率。
延伸问答
Apache Spark 4.1有哪些主要的新特性?
Apache Spark 4.1增强了Spark Connect的稳定性,支持Python客户端的Spark ML,新增VARIANT数据类型,扩展SQL功能,支持递归CTE等。
VARIANT数据类型在Spark 4.1中有什么优势?
VARIANT数据类型支持半结构化数据存储,性能显著提升,读取速度比标准VARIANT快8倍,比JSON字符串快30倍。
Spark 4.1如何改善机器学习性能?
Spark 4.1引入了模型大小估算机制和优化的模型缓存,提升了机器学习的稳定性和内存利用率。
Spark 4.1的SQL功能有哪些扩展?
Spark 4.1扩展了SQL语言,支持复杂数据处理、递归CTE和SQL脚本,增强了数据仓库与数据工程的桥梁。
如何下载Apache Spark 4.1?
Apache Spark 4.1是完全开源的,可以从spark.apache.org下载。
Spark 4.1中引入的递归CTE有什么用?
递归CTE允许在SQL中遍历层次数据结构,简化了从遗留系统迁移的过程。
