
优化物化视图的重新计算
内容提要
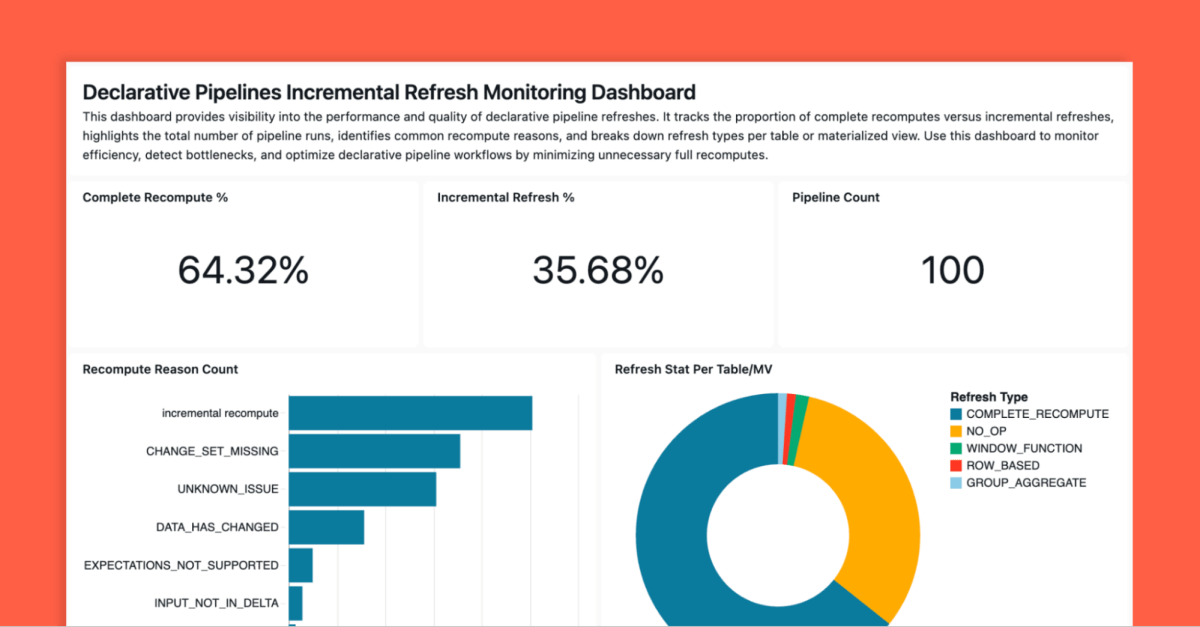
物化视图(MV)通过存储预计算的查询结果来提升查询性能并降低计算成本。Lakeflow声明式管道(LDP)支持MV的增量刷新,Enzyme引擎智能更新MV以减少资源消耗。增量刷新适用于小变更,而全刷新适用于重大变更。启用行跟踪和删除向量可优化MV更新。使用非确定性函数会触发全刷新,建议将其值推入源表。
关键要点
-
物化视图(MV)通过存储预计算的查询结果来提升查询性能,降低计算成本。
-
Lakeflow声明式管道(LDP)支持MV的增量刷新,Enzyme引擎智能更新MV以减少资源消耗。
-
增量刷新适用于小变更,而全刷新适用于重大变更。
-
启用行跟踪和删除向量可优化MV更新。
-
使用非确定性函数会触发全刷新,建议将其值推入源表。
-
全刷新会重新处理所有数据,成本高且耗时。
-
增量刷新适用于小变更,能有效降低计算成本。
-
Enzyme引擎智能处理新数据,减少资源消耗和延迟。
-
启用行跟踪可检测自上次MV刷新以来的行变更。
-
启用删除向量可跟踪已删除的行,避免重写整个文件。
-
技术解决方案包括生成Delta表、创建LDP、添加非确定性函数等步骤。
-
添加非确定性函数会导致MV无法增量刷新,建议将其值推入源表。
-
全刷新可由非确定性函数、复杂连接等条件自动触发。
延伸解读
物化视图的增量刷新与全刷新
物化视图的增量刷新适用于小规模变更,能够有效降低计算成本。而全刷新则适合于数据发生重大变化的情况,尽管其成本较高且耗时。了解何时使用增量刷新或全刷新对优化数据处理流程至关重要。
Enzyme引擎的智能更新
Enzyme引擎通过智能分析新数据对查询结果的影响,仅更新必要的数据,从而显著降低资源消耗和延迟。这种方法相比传统的批处理ETL方法更为高效,适合需要频繁更新数据的场景。
非确定性函数的影响
使用非确定性函数(如RANDOM())会触发物化视图的全刷新,导致无法进行增量更新。为了避免这种情况,建议将非确定性值推入源表中,这样可以保持增量刷新的能力,提升数据处理效率。
延伸问答
什么是物化视图,它的主要作用是什么?
物化视图(MV)是存储预计算查询结果的表,主要用于提升查询性能和降低计算成本。
增量刷新和全刷新有什么区别?
增量刷新适用于小变更,效率高;全刷新则重新处理所有数据,适用于重大变更,但成本高且耗时。
如何优化物化视图的更新过程?
可以通过启用行跟踪和删除向量来优化物化视图的更新,减少资源消耗。
使用非确定性函数对物化视图有什么影响?
使用非确定性函数会触发全刷新,建议将其值推入源表以避免影响增量刷新。
Enzyme引擎如何提高物化视图的更新效率?
Enzyme引擎智能处理新数据,仅更新必要部分,从而减少资源消耗和延迟。
在什么情况下应该使用全刷新?
当底层数据发生重大变化,特别是记录被删除或修改时,应使用全刷新。
