
实践中的代理推理:理解结构化与非结构化数据
内容提要
Databricks的Supervisor Agent(SA)通过多步骤推理,结合结构化和非结构化数据,提升企业任务处理效率。SA在学术检索和金融分析等知识密集型任务中表现优异,灵活架构允许用户通过简单配置优化性能,无需编写代码。SA有效分解复杂问题,整合多种数据源,提高检索和推理能力。
关键要点
-
Databricks的Supervisor Agent(SA)通过多步骤推理,结合结构化和非结构化数据,提升企业任务处理效率。
-
SA在学术检索、金融分析等知识密集型任务中表现优异,能够有效分解复杂问题并整合多种数据源。
-
SA的灵活架构允许用户通过简单配置优化性能,无需编写代码。
-
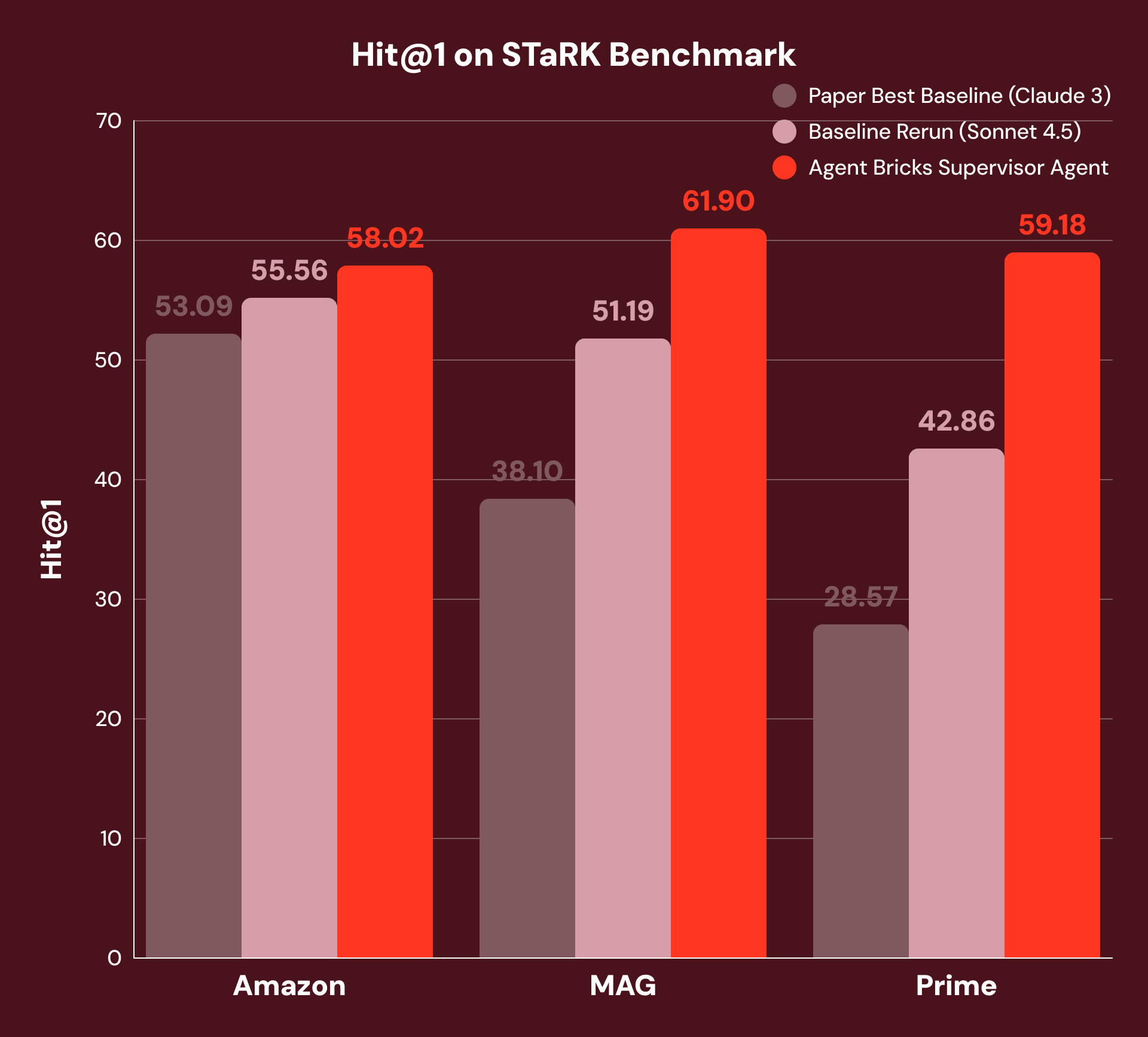
SA在多个基准测试中表现出显著的性能提升,例如在STaRK-MAG上提高了21%,在FinanceBench上提高了23%。
-
SA能够处理复杂查询,通过协调搜索计划和分解任务来提高检索和推理能力。
-
构建高性能代理的关键在于编写精确的指令和配备合适的工具,而不是从头开始构建新系统。
延伸解读
多步骤推理的优势
Databricks的Supervisor Agent(SA)通过多步骤推理有效整合结构化与非结构化数据,显著提升了任务处理效率。这种方法特别适合需要综合多种数据源的复杂查询,能够在学术检索和金融分析等领域取得优异表现。用户可以通过简单配置优化性能,降低了技术门槛。
灵活架构的实用性
SA的灵活架构使得用户无需编写代码即可调整指令和工具配置,从而适应不同的企业任务。这种设计不仅提高了系统的可用性,还允许用户根据实际需求不断优化代理的表现,适应快速变化的业务环境。
性能基准与比较
在多个基准测试中,SA表现出显著的性能提升,尤其是在需要紧密结合结构化与非结构化数据的任务中。与传统的单轮系统相比,SA能够更好地处理复杂查询,避免了信息遗漏,展现出更高的检索和推理能力。
延伸问答
Databricks的Supervisor Agent(SA)如何提升企业任务处理效率?
SA通过多步骤推理,结合结构化和非结构化数据,能够有效分解复杂问题并整合多种数据源,从而提升任务处理效率。
Supervisor Agent在学术检索和金融分析中表现如何?
SA在学术检索中提高了21%的性能,在金融分析中提高了23%的性能,表现优异。
使用Supervisor Agent需要编写代码吗?
不需要,SA的灵活架构允许用户通过简单配置优化性能,无需编写代码。
构建高性能代理的关键是什么?
构建高性能代理的关键在于编写精确的指令和配备合适的工具,而不是从头开始构建新系统。
Supervisor Agent如何处理复杂查询?
SA通过协调搜索计划和分解任务来处理复杂查询,提高检索和推理能力。
SA在基准测试中的表现如何?
SA在多个基准测试中表现出显著的性能提升,例如在STaRK-MAG上提高了21%,在FinanceBench上提高了23%。
