
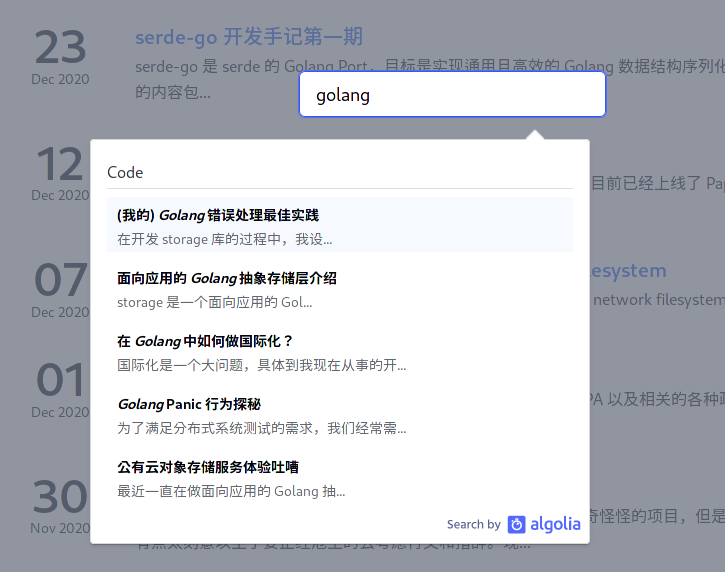
Hugo 基于 DocSearch 实现全文搜索
内容提要
本文介绍了如何在Hugo博客中实现基于DocSearch的全文搜索。通过使用docsearch-scraper爬虫和Hugo模板机制,生成符合DocSearch要求的数据结构,并详细说明了数据构造、索引文件创建及Algolia数据更新的方法,最终实现简单的搜索功能。
关键要点
-
DocSearch 是由 docsearch-scraper 爬虫和前端实现组成,主要用于文档搜索。
-
使用 docsearch-scraper 可以抓取网站并生成符合要求的数据格式。
-
构造数据有两种方案:运行 docsearch crawler 或使用 Hugo 内置的模板机制。
-
选择使用 Hugo 模板机制可以简化构建流程并避免超出免费额度。
-
生成的数据结构包括 objectID、type、hierarchy 和 content,通常博客内容不够结构化。
-
通过 CSS 隐藏不需要的部分,确保 DocSearch 正常工作。
-
在构建流程中使用 atomic-algolia 更新 Algolia 数据,减少更新次数。
-
需要设置环境变量以便在构建时更新 Algolia 数据。
延伸解读
DocSearch 的适用性
DocSearch 主要面向文档类网站,博客内容通常不够结构化,因此在使用时需注意数据格式的匹配。通过 Hugo 的模板机制,可以更灵活地生成符合要求的数据结构,避免直接使用爬虫带来的复杂性和数据冗余。
构建流程的简化
选择使用 Hugo 内置的模板机制可以显著简化构建流程,尤其是在处理非结构化内容时。通过合理设计数据结构,可以有效避免超出 Algolia 的免费额度,同时确保搜索功能的正常运行。
环境变量的设置
在构建过程中,需要正确设置环境变量以更新 Algolia 数据。确保这些变量的配置无误,可以避免构建失败或数据更新不及时的问题,提升搜索功能的稳定性。
延伸问答
如何在Hugo博客中实现DocSearch的全文搜索?
可以通过使用docsearch-scraper爬虫和Hugo模板机制生成符合DocSearch要求的数据结构,从而实现全文搜索。
使用docsearch-scraper的好处是什么?
使用docsearch-scraper可以抓取网站并生成符合要求的数据格式,简化数据构造流程。
在构建DocSearch时需要注意哪些数据结构?
需要生成包含objectID、type、hierarchy和content的数据结构,通常博客内容不够结构化,可以提交空的hierarchy。
如何避免在使用docsearch-crawler时超出免费额度?
可以选择使用Hugo内置的模板机制来生成索引文件,从而简化构建流程并避免超出免费额度。
如何在构建流程中更新Algolia数据?
可以使用atomic-algolia来原子化更新Algolia数据,只更新发生变更的数据,减少更新次数。
在Hugo中如何隐藏DocSearch的某些部分?
可以通过CSS隐藏不需要的部分,例如使用display: none来隐藏特定的搜索建议内容。
