
如何加速 COUNT(DISTINCT)
原文英文,约3700词,阅读约需14分钟。
📝
内容提要
在应用程序中,计数是常见的操作,但有时仅仅计数是不够的。本文介绍了加快COUNT(DISTINCT) SQL查询速度的方法,并提供了程序化的解决方案。
🎯
关键要点
-
计数是应用程序中的常见操作,但有时需要计算唯一用户或不同项目的数量。
-
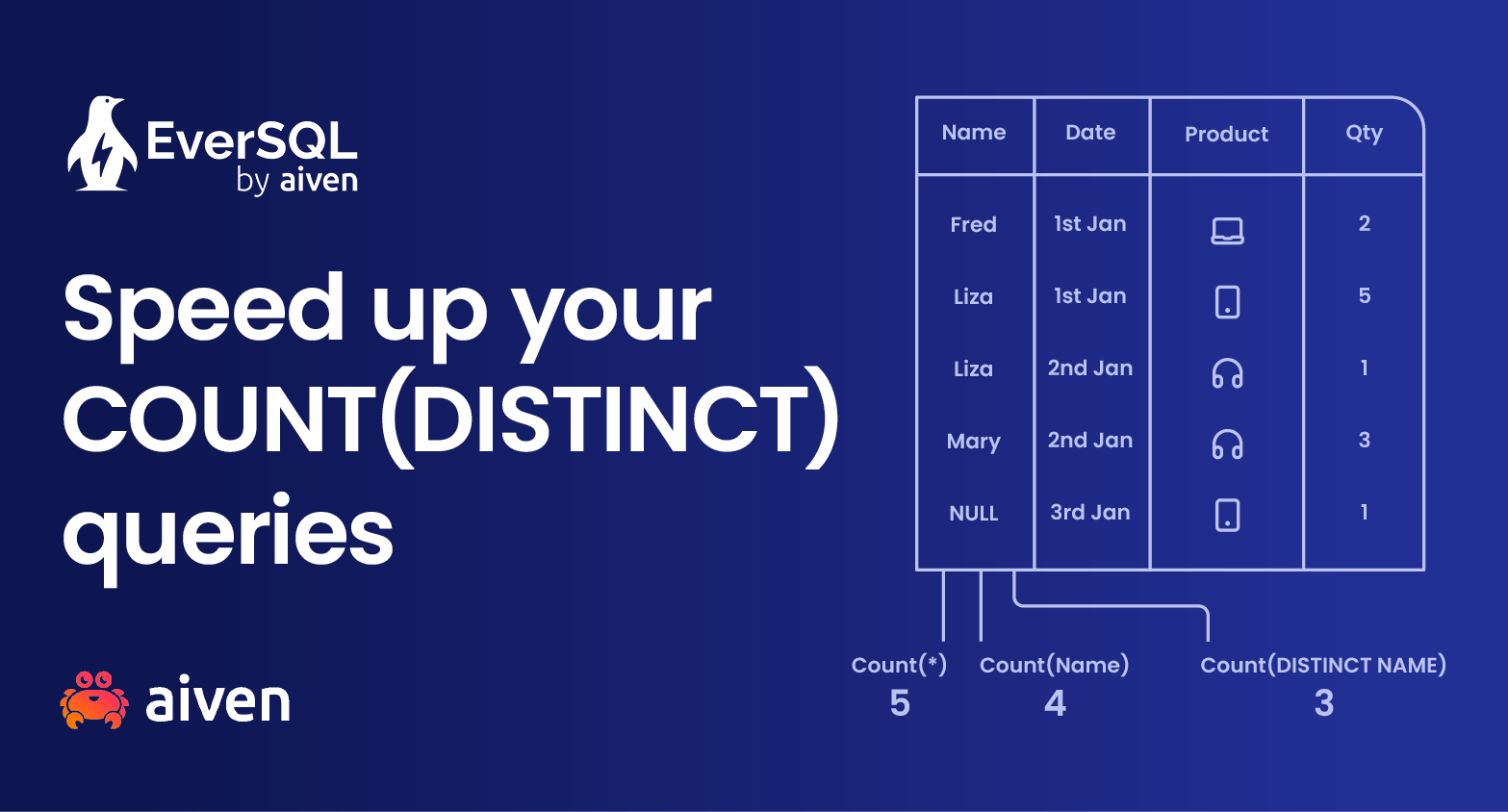
COUNT(DISTINCT) 通常比 COUNT(*) 慢,因为它需要列出唯一值并进行计数。
-
COUNT(*) 返回查询结果的行数,而 COUNT(field) 只计算非 NULL 行的数量。
-
COUNT(DISTINCT field) 计算不同的非 NULL 值的数量。
-
加速 COUNT(DISTINCT) 查询的方法有至少 7 种,适用于不同需求。
-
可以使用数据库的基数估计来加速 COUNT(DISTINCT) 查询,尤其在不需要精确数字时。
-
使用 EXPLAIN 命令的结果可以提供更好的估计,尤其是对于复杂查询。
-
通过聚合和物化视图可以提高 COUNT(DISTINCT) 查询的性能。
-
HyperLogLog 数据结构可以用于近似计数,适合于稀疏写入的工作负载。
-
创建覆盖索引可以加速 COUNT(DISTINCT) 查询,避免全表扫描。
-
重新评估 COUNT(DISTINCT) 的必要性,有时可以通过 EXISTS 子查询来优化查询。
-
在某些情况下,可以通过 LIMIT 子句提供结果的粗略估计,而不需要精确的 COUNT(DISTINCT)。
-
检查是否真的是 COUNT(DISTINCT) 的问题,可能其他部分导致查询性能慢。
-
程序化的方法可以帮助识别和加速慢的 COUNT(DISTINCT) 查询。
🏷️
