

用 Rust 从零写一个分布式 ID 生成服务
💡
原文中文,约9000字,阅读约需22分钟。
📝
内容提要
本文探讨了使用 Rust 实现的分布式 ID 生成服务,支持 Snowflake、ULID 和 NanoID 三种算法,分析了各算法的优缺点,项目结构设计,核心接口定义及存储层实现,强调了 Rust 的类型系统和异步特性。
🎯
关键要点
- 分布式 ID 生成服务解决了数据库自增 ID 冲突的问题。
- 支持三种主流算法:Snowflake、ULID 和 NanoID,各有优缺点。
- Snowflake 生成 64 位整数,按时间有序,但依赖机器时钟。
- ULID 生成 26 个字符的字符串,字典序可排序,适合数据库索引。
- NanoID 生成随机字符串,短小精悍,适合短链接场景。
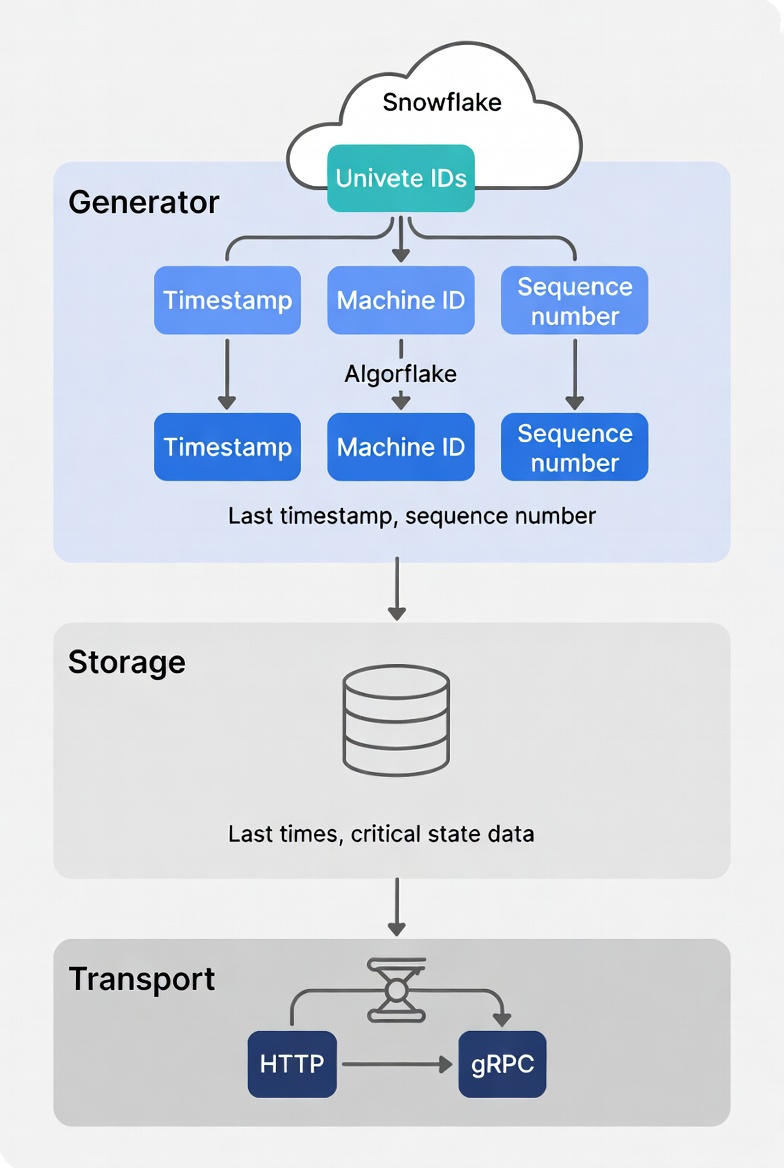
- 项目结构分为三层:Generator、Storage 和 Transport,便于替换和扩展。
- 核心接口定义使用枚举统一 ID 格式,支持不同算法的 ID 生成。
- 存储层实现包括内存存储和文件存储,适应不同场景需求。
- Snowflake 实现需处理时钟回拨和序列号耗尽的问题。
- ULID 采用 Crockford's Base32 编码,确保字典序和 URL 安全。
- NanoID 使用掩码和拒绝采样方法,确保随机字符均匀分布。
- HTTP 和 gRPC 服务提供了简单的接口供外部调用。
- 命令行工具支持多种算法和存储方式,方便直接运行。
- 项目体现了 Rust 的类型系统、异步特性和灵活的设计理念。
➡️
