
用 Rust 从零写一个分布式 ID 生成服务
内容提要
本文探讨了使用 Rust 实现的分布式 ID 生成服务,支持 Snowflake、ULID 和 NanoID 三种算法,分析了各算法的优缺点,项目结构设计,核心接口定义及存储层实现,强调了 Rust 的类型系统和异步特性。
关键要点
-
分布式 ID 生成服务解决了数据库自增 ID 冲突的问题。
-
支持三种主流算法:Snowflake、ULID 和 NanoID,各有优缺点。
-
Snowflake 生成 64 位整数,按时间有序,但依赖机器时钟。
-
ULID 生成 26 个字符的字符串,字典序可排序,适合数据库索引。
-
NanoID 生成随机字符串,短小精悍,适合短链接场景。
-
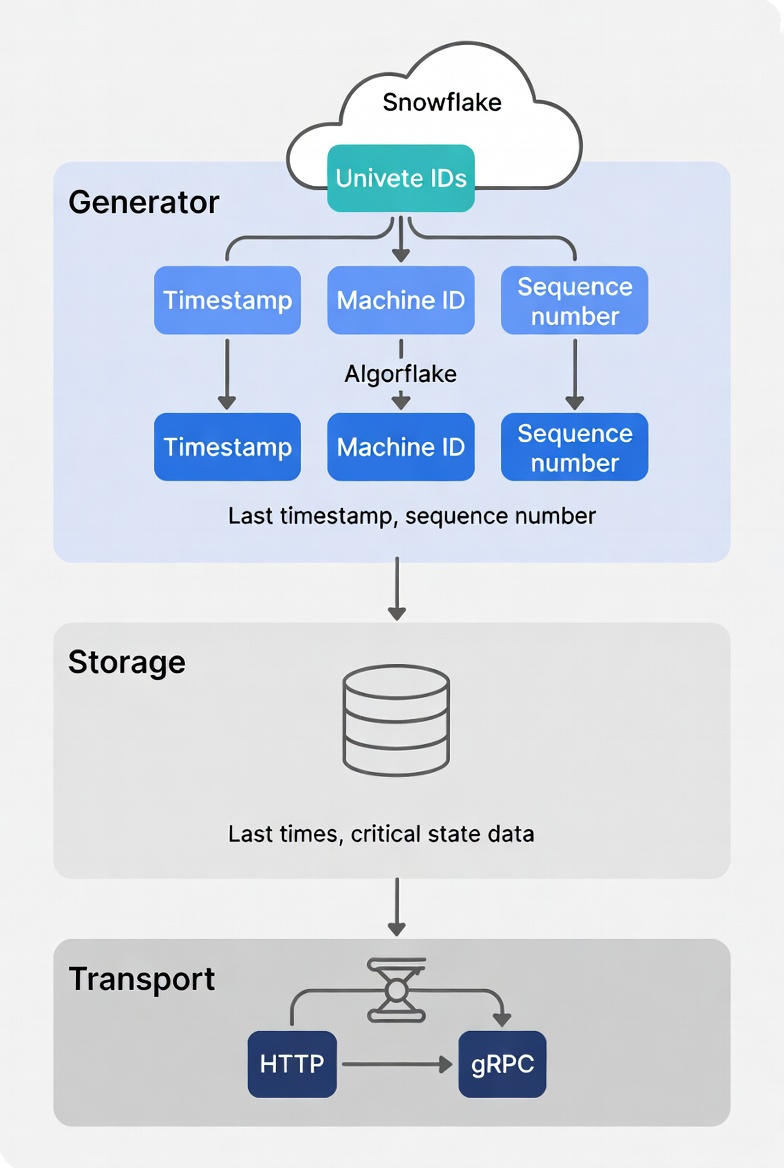
项目结构分为三层:Generator、Storage 和 Transport,便于替换和扩展。
-
核心接口定义使用枚举统一 ID 格式,支持不同算法的 ID 生成。
-
存储层实现包括内存存储和文件存储,适应不同场景需求。
-
Snowflake 实现需处理时钟回拨和序列号耗尽的问题。
-
ULID 采用 Crockford's Base32 编码,确保字典序和 URL 安全。
-
NanoID 使用掩码和拒绝采样方法,确保随机字符均匀分布。
-
HTTP 和 gRPC 服务提供了简单的接口供外部调用。
-
命令行工具支持多种算法和存储方式,方便直接运行。
-
项目体现了 Rust 的类型系统、异步特性和灵活的设计理念。
延伸解读
分布式 ID 生成的必要性
在分库分表的场景中,传统的自增 ID 可能导致冲突,因此需要分布式 ID 生成服务。通过使用如 Snowflake、ULID 和 NanoID 等算法,可以有效避免 ID 冲突,确保数据的唯一性和一致性。
算法优缺点分析
不同的 ID 生成算法各有优缺点。Snowflake 生成的 ID 按时间有序,但依赖机器时钟,可能面临时钟回拨的问题;ULID 则提供了字典序排序,适合数据库索引;而 NanoID 则适合短链接场景,生成的 ID 更短且随机性强。选择合适的算法需根据具体应用场景而定。
项目结构设计的灵活性
该项目采用三层架构设计,分别为 Generator、Storage 和 Transport。这种设计使得每一层都可以独立替换,增强了系统的灵活性和可扩展性。例如,若需要更换存储方式,只需实现相应的 Storage trait,而不影响 ID 生成逻辑。
延伸问答
分布式 ID 生成服务的主要功能是什么?
分布式 ID 生成服务解决了数据库自增 ID 冲突的问题,支持多种算法生成唯一 ID。
Snowflake、ULID 和 NanoID 各自的优缺点是什么?
Snowflake 生成有序的 64 位整数,但依赖机器时钟;ULID 生成 26 个字符的字符串,字典序可排序;NanoID 生成短小的随机字符串,适合短链接。
如何设计分布式 ID 生成服务的项目结构?
项目结构分为三层:Generator 负责生成 ID,Storage 负责持久化状态,Transport 负责对外提供服务。
如何处理 Snowflake 算法中的时钟回拨问题?
时钟回拨会导致生成重复 ID,可以选择报错或等待时钟追上,建议配合 NTP 使用。
ULID 的编码方式是什么?
ULID 使用 Crockford's Base32 编码,确保字典序和 URL 安全,最终生成 26 个字符的字符串。
NanoID 如何确保随机字符的均匀分布?
NanoID 使用掩码和拒绝采样的方法,确保随机字符均匀分布在字母表中。
