通过合成预训练释放语言模型的潜力
原文英文,约800词,阅读约需3分钟。发表于:。This is a Plain English Papers summary of a research paper called Unlocking language models' potential through synthetic pretraining. If you like these kinds of analysis, you should join...
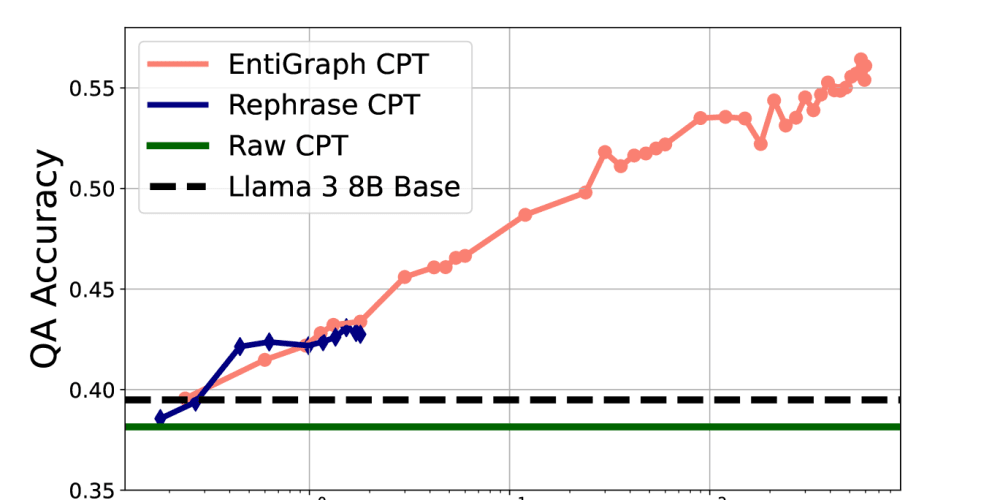
本文介绍了合成持续预训练方法,通过在合成数据上微调预训练模型来提高语言模型性能。该方法能够帮助模型学习到原始数据中不存在的模式和细微差别,提高在各种任务上的表现。研究还探讨了生成合成数据的不同方法,并研究了如何应用该技术改进翻译文本的模型性能。合成持续预训练为增强语言模型和开发更先进、更接近人类的人工智能系统提供了有前景的方法。