
面向自然交互式对话人工智能的音频实时通信技术进展
内容提要
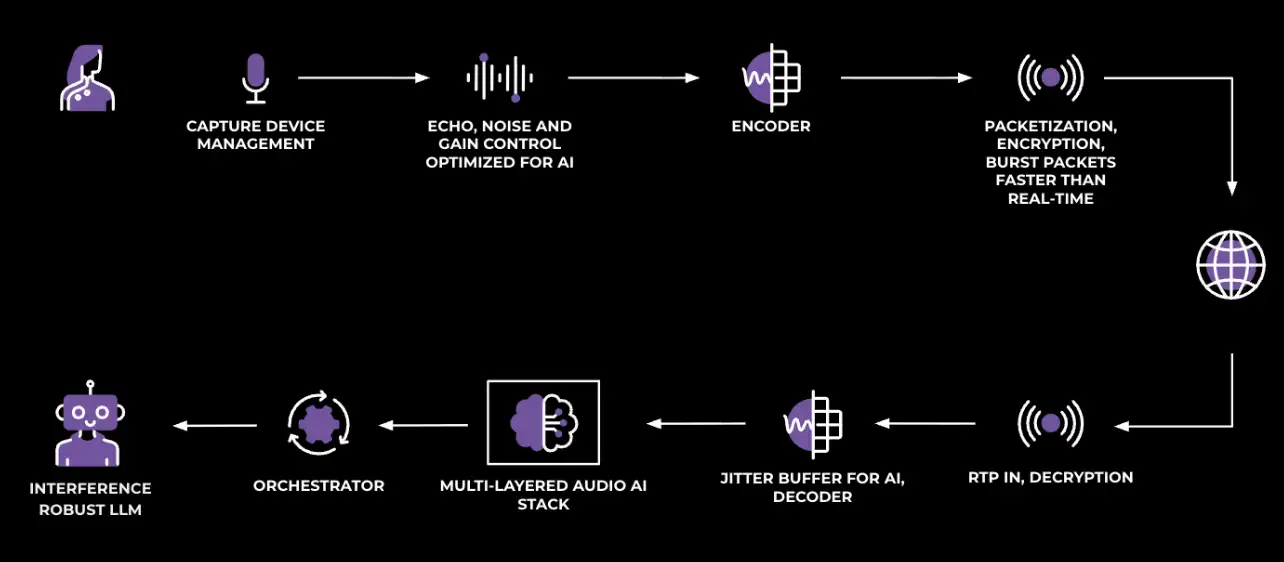
Meta开发了一套多层音频人工智能技术,旨在提升语音助手的自然交互体验。通过优化实时通信架构和增强抗干扰能力,Meta实现了更清晰的音频处理,减少背景噪音和误触发,提升响应速度。这些技术已在Meta的各类应用中应用,并将继续优化人机交互的智能化和标准化。
关键要点
-
Meta开发了一套多层音频人工智能技术,提升语音助手的自然交互体验。
-
通过优化实时通信架构,增强抗干扰能力,实现更清晰的音频处理。
-
技术减少背景噪音和误触发,提升响应速度。
-
目标是实现与人工智能的真正免提全双工对话。
-
优化架构以实现即时连接、降低延迟并增强容错能力。
-
采用增强数据进行训练,提升大型语言模型的抗干扰能力。
-
模块化音频堆栈简化调试流程,加速迭代。
-
近/远说话人检测模块能识别说话者距离,过滤背景噪音。
-
主要说话人分割系统无需注册,能够即时识别新说话人。
-
回声控制结合客户端和服务器端技术,防止机器人对自身声音反应。
-
模块化设计使得系统可观察和可调整,快速迭代以解决用户反馈问题。
-
技术在嘈杂环境中表现良好,减少背景噪音和干扰。
-
未来发展方向包括更智能的编解码器和设备边缘上下文信息的提供。
延伸解读
技术背景与应用场景
Meta的音频人工智能技术旨在提升语音助手的自然交互体验,尤其在嘈杂环境中表现出色。这项技术的应用场景包括日常生活中的语音助手、可穿戴设备以及社交媒体应用,能够有效减少背景噪音和误触发,提高用户的交互满意度。
模块化设计的优势
Meta采用模块化音频堆栈设计,使得系统可观察和可调整,能够快速响应用户反馈。这种设计不仅简化了调试流程,还加速了技术迭代,确保在不断变化的环境中保持高效的音频处理能力。
未来发展方向
未来,Meta计划开发更智能的编解码器,并提供设备边缘的上下文信息,以实现更流畅的AI交互。这将进一步提升语音助手的响应速度和准确性,使其在复杂环境中更具实用性。
延伸问答
Meta开发的音频人工智能技术有什么主要目标?
Meta的主要目标是实现与人工智能的真正免提全双工对话,提升语音助手的自然交互体验。
Meta的音频技术如何减少背景噪音和误触发?
通过优化实时通信架构和增强抗干扰能力,Meta的技术能够实现更清晰的音频处理,减少背景噪音和误触发。
Meta的音频技术在嘈杂环境中的表现如何?
该技术在嘈杂环境中表现良好,能够有效减少背景噪音和干扰,提高语音助手的响应速度。
Meta的音频人工智能技术是如何进行训练的?
技术采用包含真实环境背景噪声、重叠语音及回声场景的增强数据进行训练,以提升大型语言模型的抗干扰能力。
Meta的模块化音频堆栈有什么优势?
模块化音频堆栈简化了调试流程,加速了迭代,并能在处理前过滤干扰信号,提高系统的鲁棒性。
未来Meta在音频技术方面有哪些发展方向?
未来发展方向包括开发更智能的编解码器和提供设备边缘上下文信息,以实现更流畅的AI交互。
