
5行评估任务的5万次运行教会了我们什么
内容提要
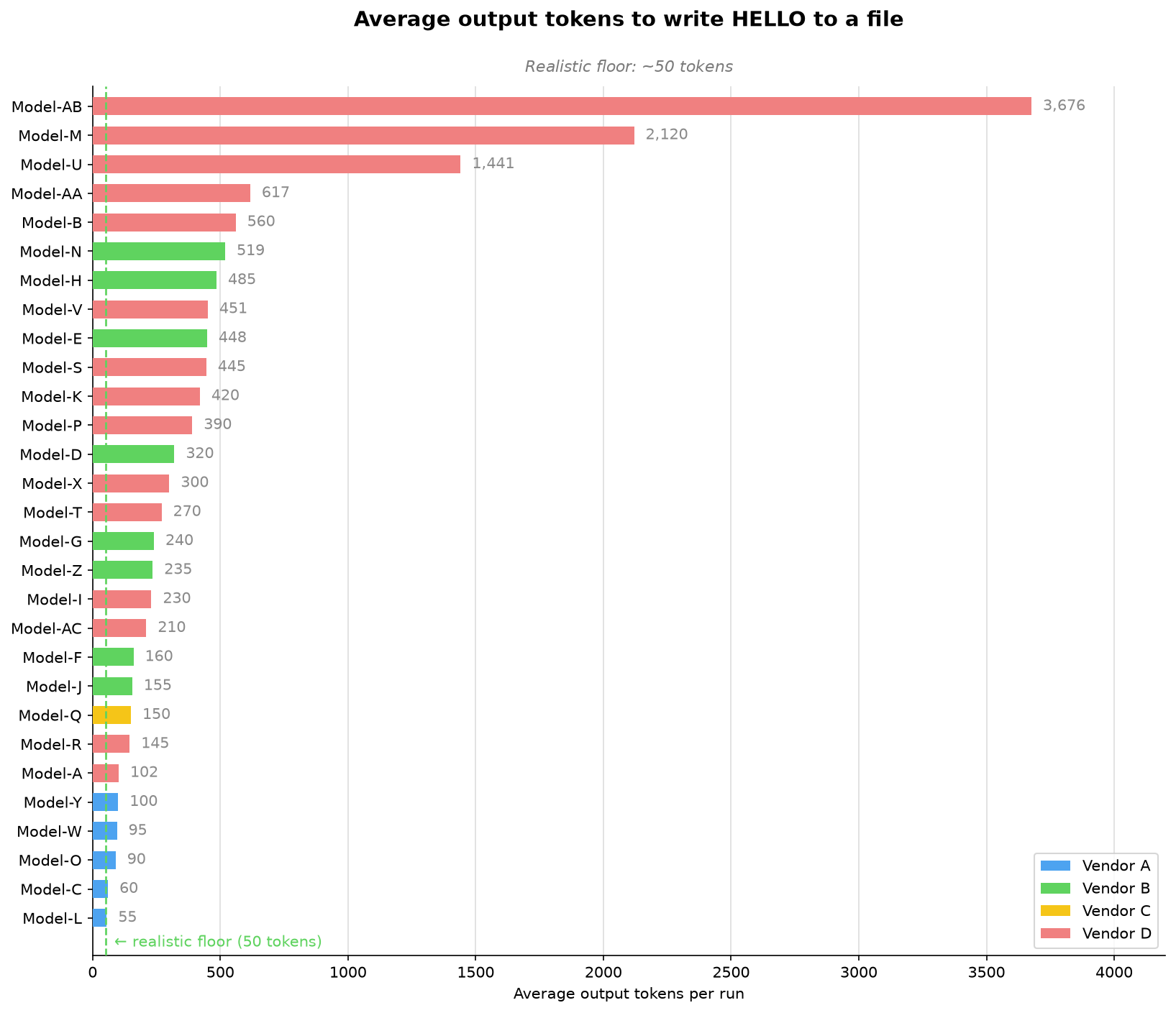
VS Code团队通过简单的“say_hello”任务评估模型表现,发现不同模型在处理请求时效率差异。尽管所有模型都能完成任务,但有些模型执行复杂,导致额外时间和成本。有效模型能直接完成任务,团队建议使用稳定的小任务进行评估,以捕捉模型行为变化。
关键要点
-
VS Code团队通过简单的'say_hello'任务评估模型表现,发现不同模型在处理请求时效率差异。
-
所有模型都能完成任务,但有些模型执行复杂,导致额外时间和成本。
-
有效模型能直接完成任务,避免不必要的步骤,节省时间和资源。
-
模型的表现差异体现在输出token的使用上,某些模型的token使用量远高于其他模型。
-
团队建议使用稳定的小任务进行评估,以捕捉模型行为变化,帮助优化模型选择。
-
模型选择不应成为开发者的负担,自动模型选择可以帮助选择最合适的模型。
延伸解读
模型效率的重要性
在评估模型时,效率是一个关键因素。尽管所有模型都能完成'say_hello'任务,但它们在执行过程中的复杂性和所需的输出token数量差异显著。选择一个高效的模型不仅能节省时间,还能降低成本,尤其是在处理简单任务时。
小任务的评估价值
使用简单且稳定的小任务进行模型评估,可以有效捕捉模型行为的变化。这种方法能够消除其他变量的干扰,使得模型的表现更加清晰可见。开发者可以利用这种评估方式,优化模型选择,提升工作效率。
自动模型选择的优势
随着VS Code和GitHub Copilot团队对自动模型选择的持续投资,开发者在选择模型时的负担将大大减轻。自动化的模型选择可以根据任务的需求,智能地选择最合适的模型,从而提高开发效率,减少不必要的复杂性。
延伸问答
VS Code团队通过什么任务评估模型表现?
VS Code团队通过简单的'say_hello'任务评估模型表现。
不同模型在处理请求时的效率差异如何?
不同模型在处理请求时效率差异明显,有些模型执行复杂,导致额外时间和成本。
有效模型的特点是什么?
有效模型能直接完成任务,避免不必要的步骤,节省时间和资源。
模型选择对开发者有什么影响?
模型选择不应成为开发者的负担,自动模型选择可以帮助选择最合适的模型。
为什么要使用稳定的小任务进行评估?
使用稳定的小任务进行评估可以捕捉模型行为变化,帮助优化模型选择。
模型的输出token使用量有什么意义?
输出token的使用量直接影响成本,某些模型的token使用量远高于其他模型。
