

构建的不仅仅是代理框架
Stack Overflow Blog
·
本地模型编码经验
Martin Fowler
·

介绍GeneBench-Pro
OpenAI
·

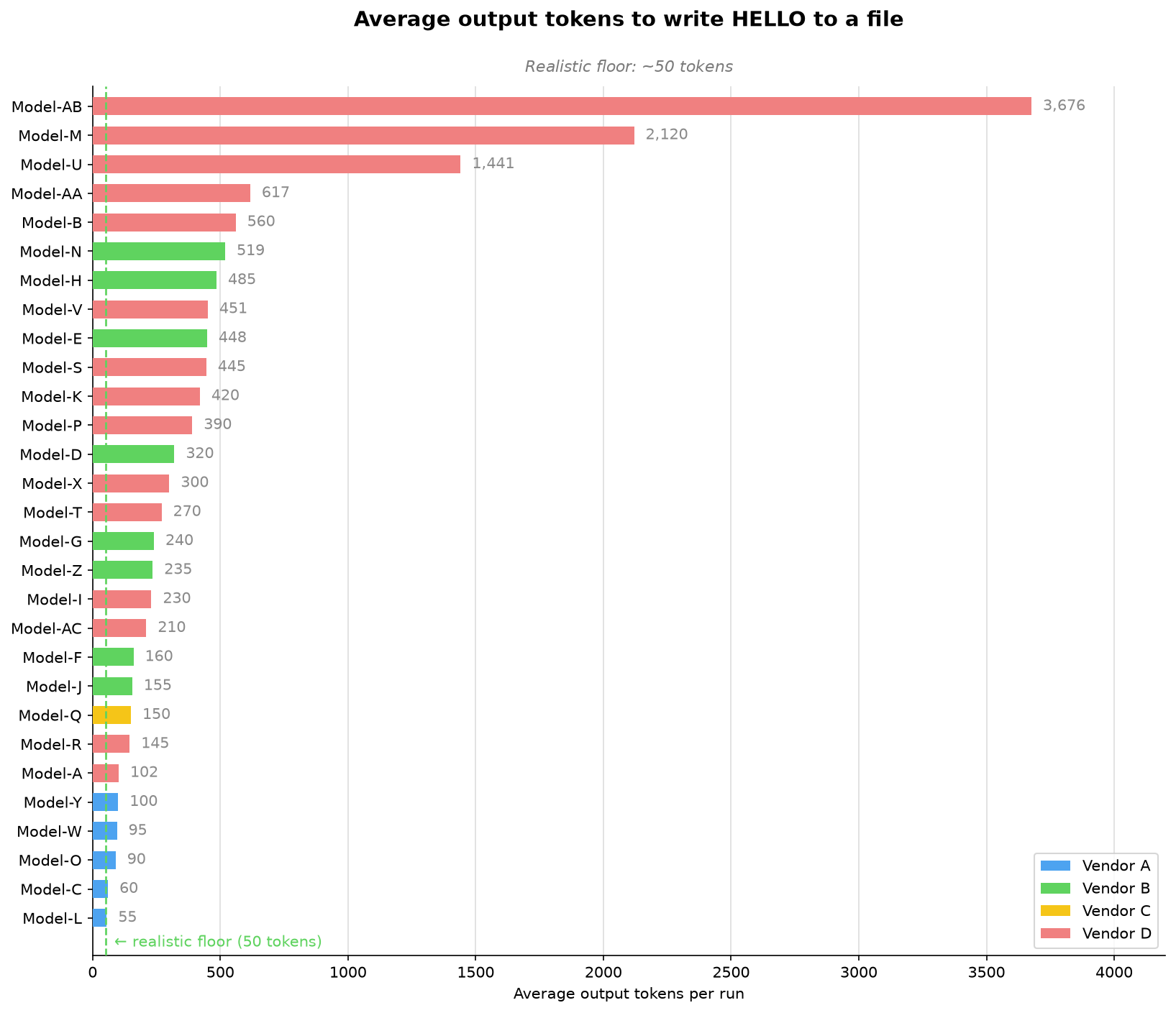
5行评估任务的5万次运行教会了我们什么
Visual Studio Code - Code Editing. Redefined.
·

通过模拟部署预测模型发布前的行为
OpenAI
·

模型评估:证明您的路由策略确实有效
The DigitalOcean Blog
·

VSAS-Bench:实时视觉流助手模型评估
Apple Machine Learning Research
·

如何在本地和云端运行开源大型语言模型
freeCodeCamp.org
·


如何使用Python和朴素贝叶斯分类器构建垃圾邮件检测器
freeCodeCamp.org
·

我们为何不再评估SWE-bench Verified
OpenAI
·

演讲:构建大规模现实应用的嵌入模型
InfoQ
·

CS231n 讲义 I:图像分类
Louis Aeilot's Blog
·
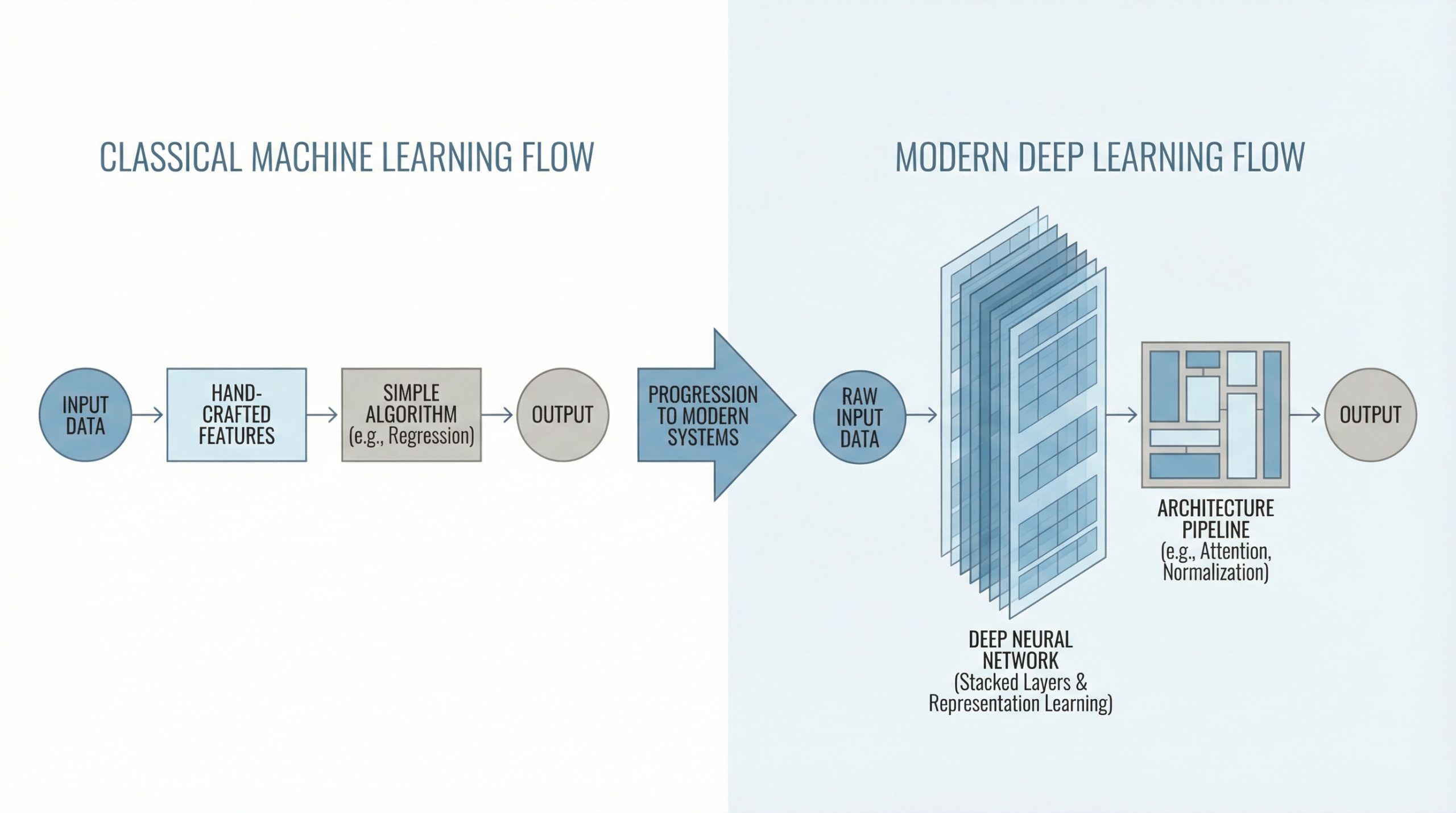
提升你的机器学习技能:安德鲁·吴课程后的行动指南
MachineLearningMastery.com
·

GIE-Bench:面向文本引导图像编辑的基础评估
Apple Machine Learning Research
·
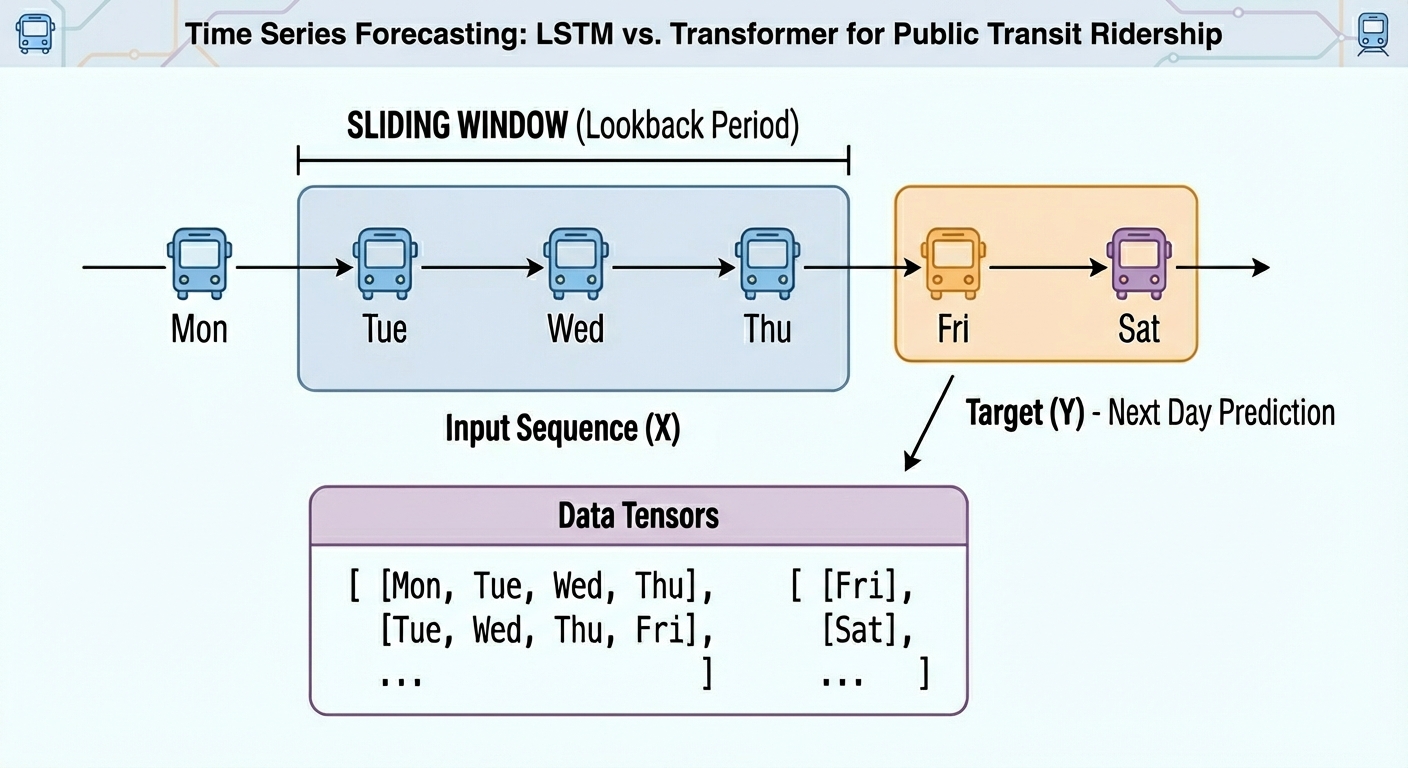
时间序列中的Transformer与LSTM:哪种效果更好?
MachineLearningMastery.com
·
