
时间序列中的Transformer与LSTM:哪种效果更好?
内容提要
本文探讨了使用LSTM和Transformer模型进行单变量时间序列预测。通过分析芝加哥公共交通数据,展示了数据预处理、模型训练和评估的过程。结果表明,两种模型的预测性能相似,Transformer略优。建议尝试不同数据集以观察模型表现的差异。
关键要点
-
本文探讨了使用LSTM和Transformer模型进行单变量时间序列预测。
-
使用芝加哥公共交通数据进行数据预处理、模型训练和评估。
-
目标是比较LSTM和Transformer在时间序列预测中的表现。
-
数据集包含2001年以来的芝加哥公共交通乘客日记录。
-
过滤掉2020年1月1日以后的数据以避免后COVID影响。
-
将时间序列数据分为训练集和测试集,前80%为训练,后20%为测试。
-
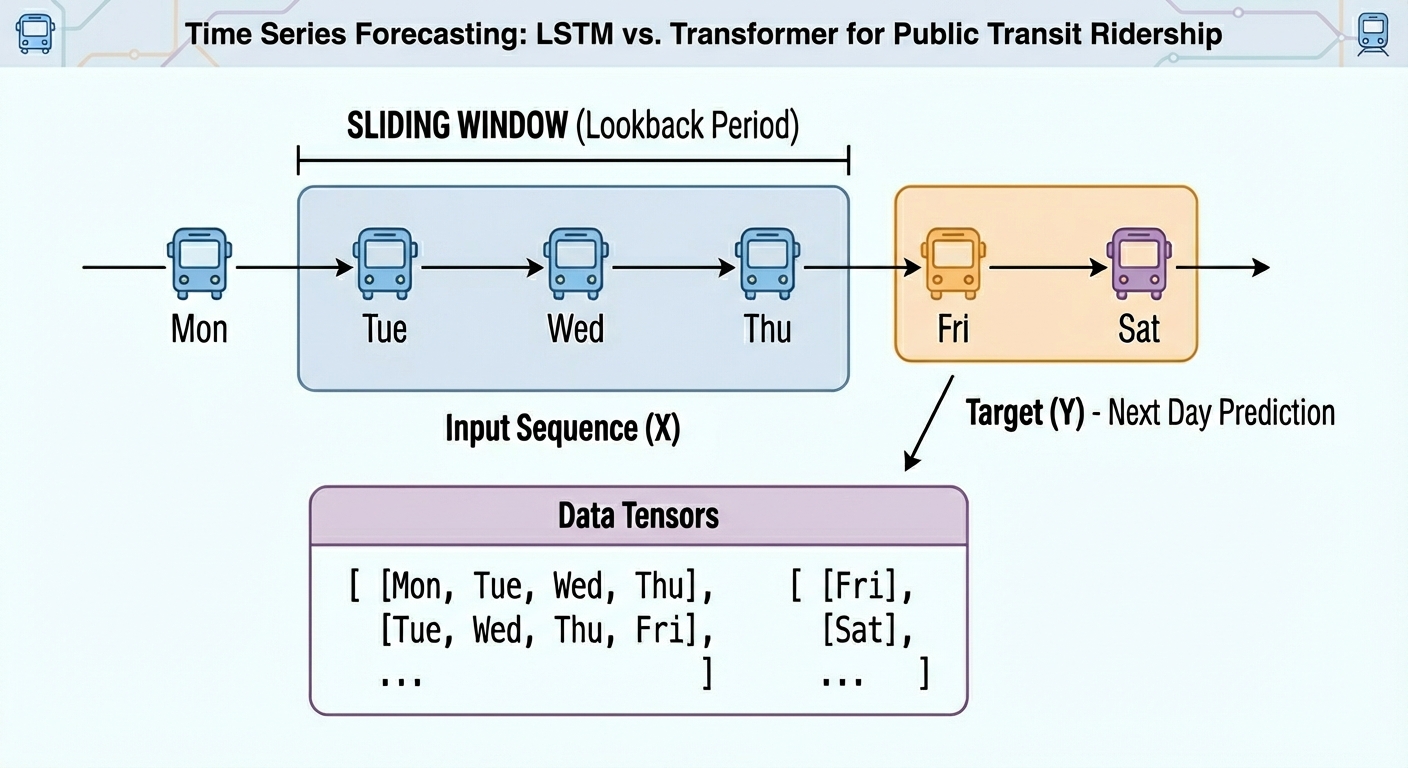
将原始时间序列转换为带标签的序列以适应神经网络训练。
-
使用PyTorch库构建LSTM和Transformer模型。
-
训练模型并使用均方根误差(RMSE)和平均绝对误差(MAE)评估性能。
-
LSTM和Transformer的预测性能相似,Transformer略优。
-
建议尝试不同数据集以观察模型表现的差异。
延伸解读
模型选择的背景
在时间序列预测中,LSTM和Transformer都是常用的深度学习模型。LSTM擅长处理序列数据的长期依赖性,而Transformer则通过自注意力机制捕捉数据中的复杂关系。选择合适的模型需要考虑数据的特性和预测的具体需求。
数据预处理的重要性
本文中对数据进行了过滤,以避免后COVID影响,这一过程对模型的预测能力至关重要。数据的质量和分布直接影响模型的训练效果,因此在实际应用中,确保数据的代表性和一致性是关键。
评估指标的解读
使用均方根误差(RMSE)和平均绝对误差(MAE)来评估模型性能是常见做法。尽管两种模型的结果相似,但在不同的应用场景中,选择合适的评估指标可以帮助更好地理解模型的优缺点。
延伸问答
LSTM和Transformer在时间序列预测中的表现如何?
LSTM和Transformer的预测性能相似,Transformer略优。
使用什么数据集进行模型训练和评估?
使用芝加哥公共交通数据集,该数据集包含2001年以来的乘客日记录。
如何处理时间序列数据以适应模型训练?
将时间序列数据分为训练集和测试集,并转换为带标签的序列以适应神经网络训练。
模型训练使用了哪些评估指标?
使用均方根误差(RMSE)和平均绝对误差(MAE)评估模型性能。
为什么LSTM和Transformer的结果如此相似?
因为这两种模型在处理遵循一致模式的单变量时间序列时都有足够的能力,且架构复杂度较低。
文章对未来的研究有什么建议?
建议尝试不同数据集以观察模型表现的差异,并在不过滤后COVID数据的情况下重复实验。
