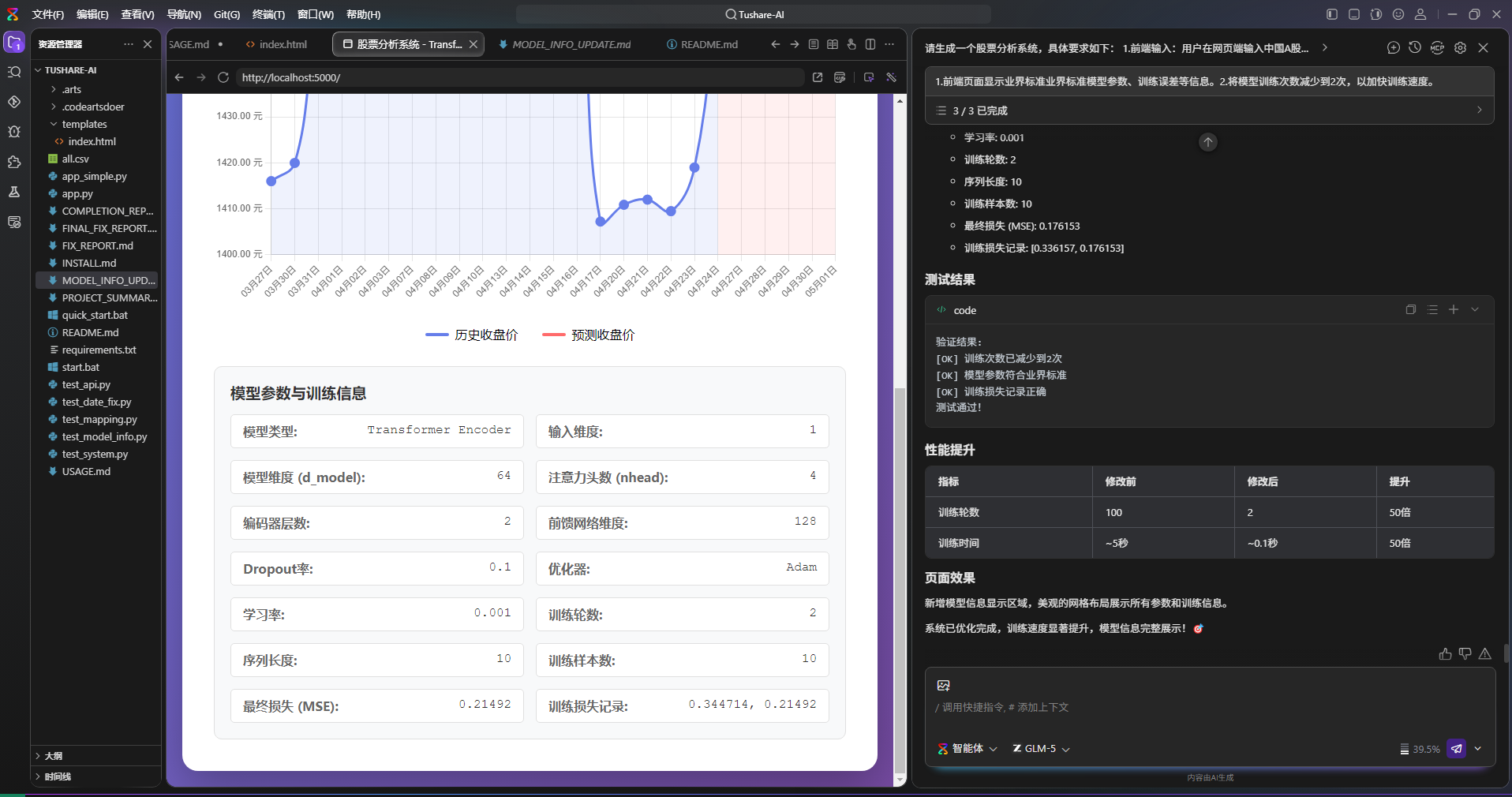
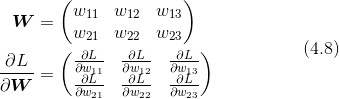
microgpt 解析
Ying’s Blog
·
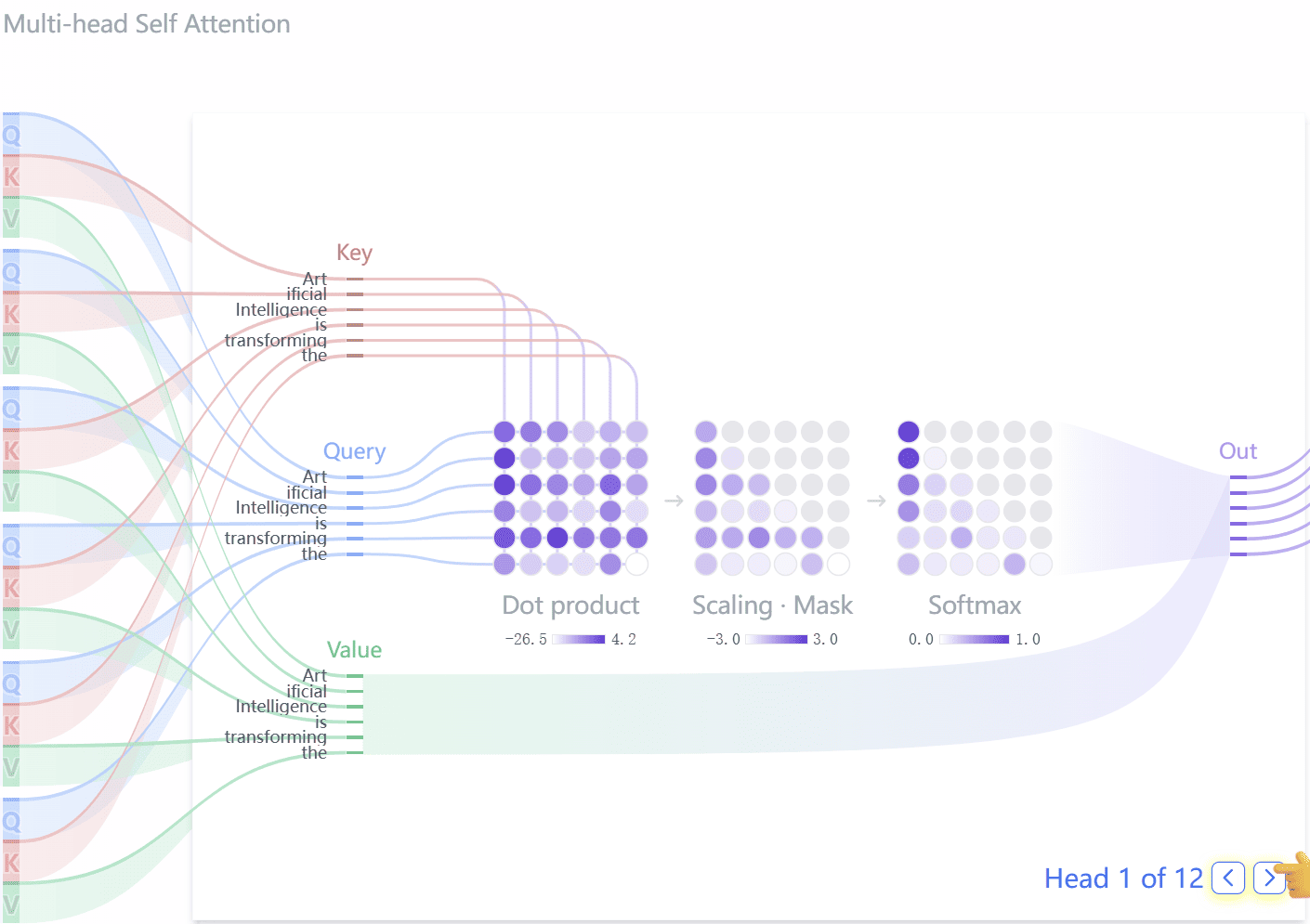
LLM 究竟是如何工作的?
鸟窝
·
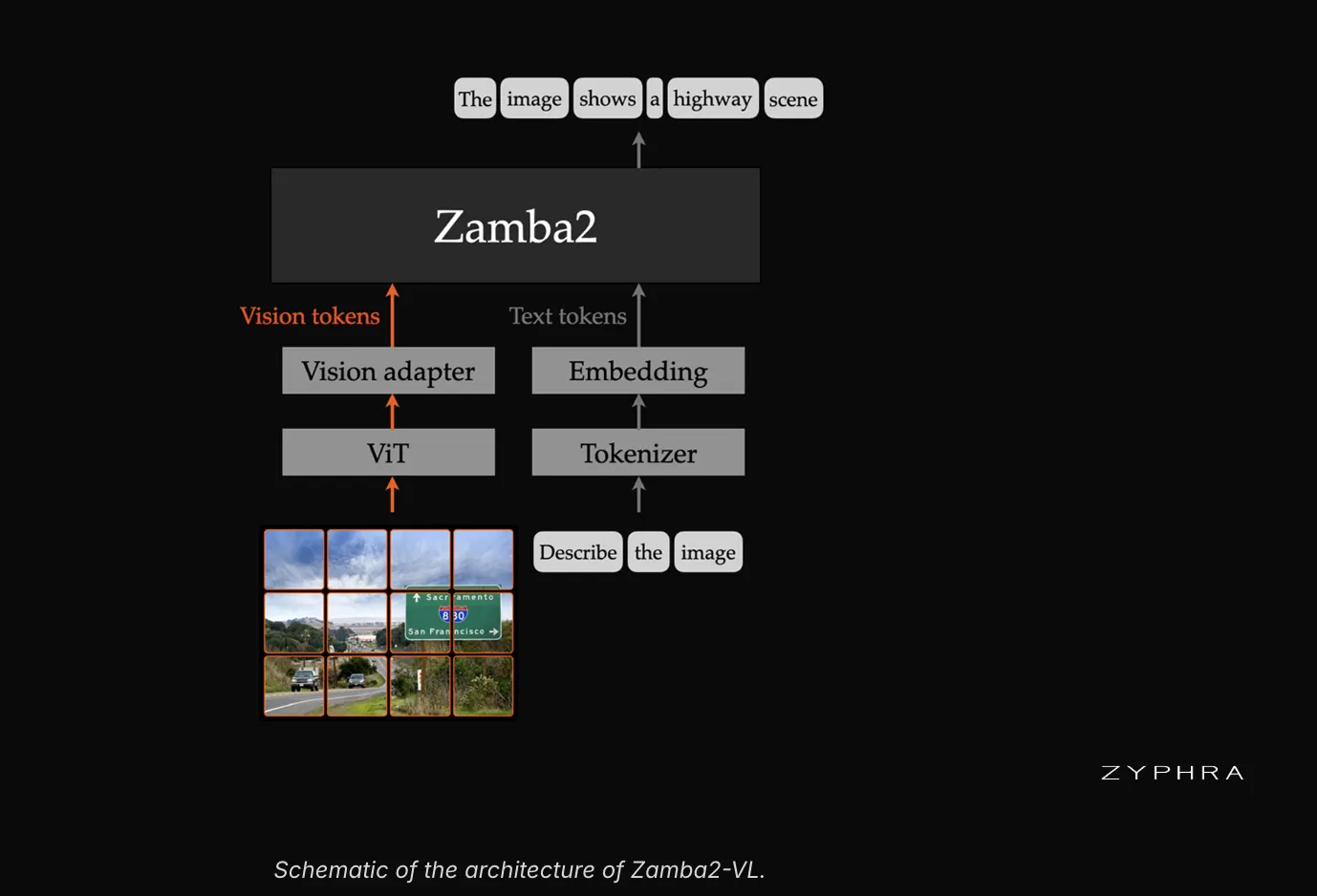
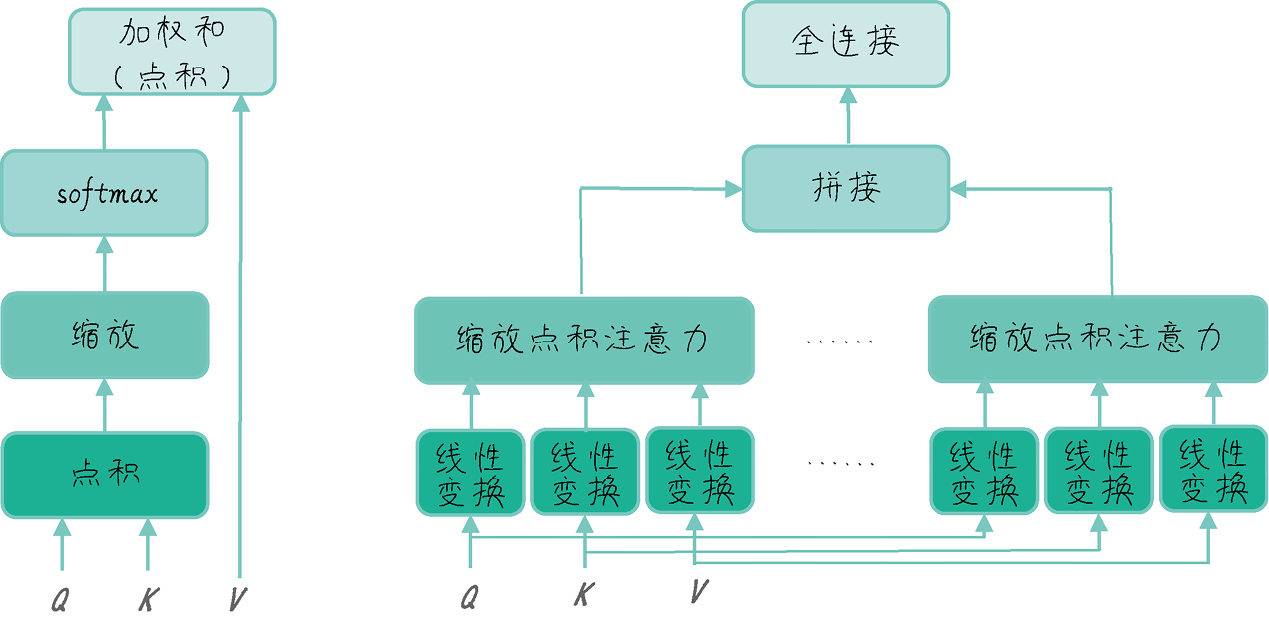
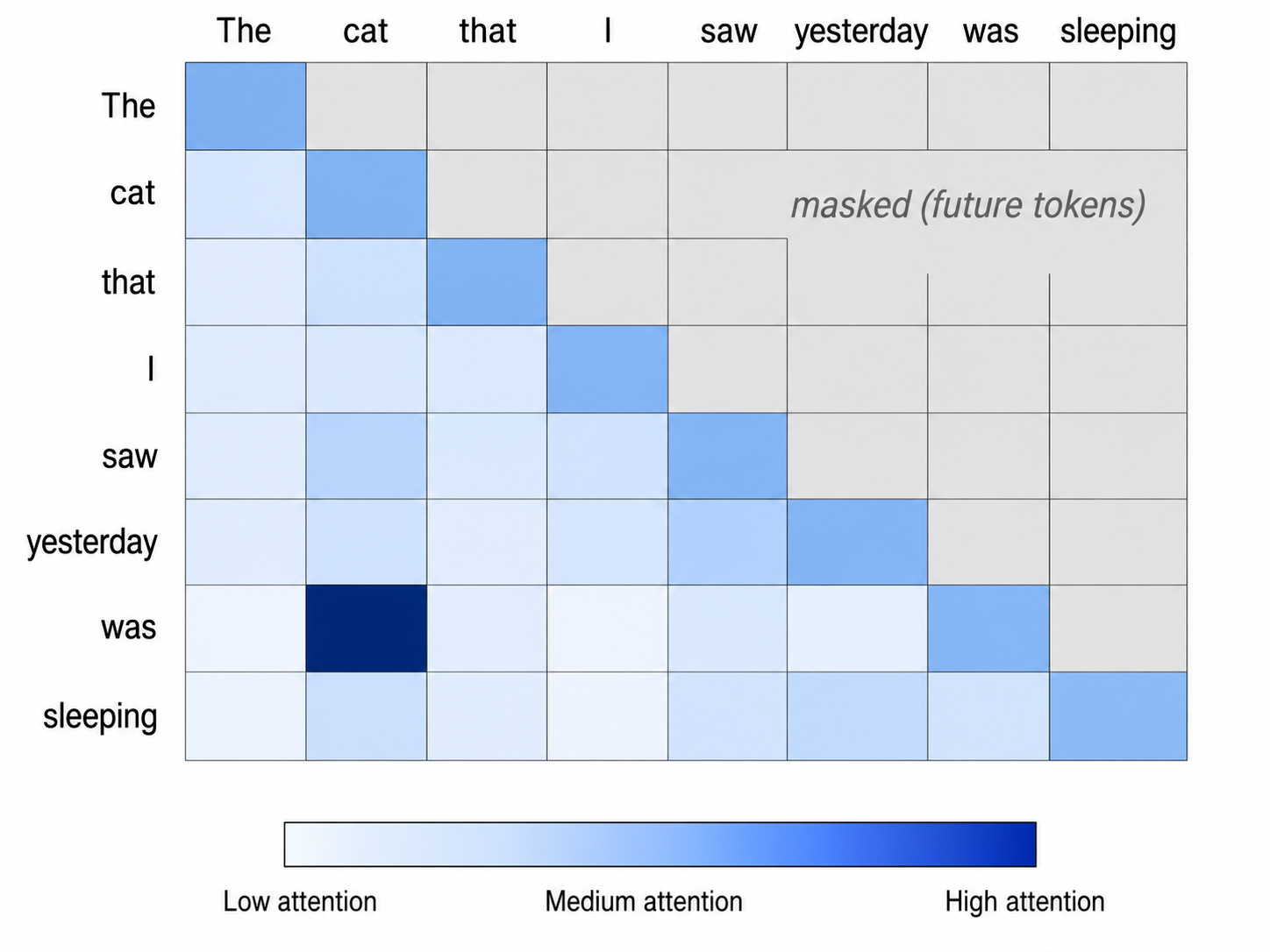
《GPT 图解》笔记:Transformer
Ying’s Blog
·

亚马逊的Panos Panay回应新款Fire手机传闻
The Verge
·