
标记的旅程:变换器内部究竟发生了什么
内容提要
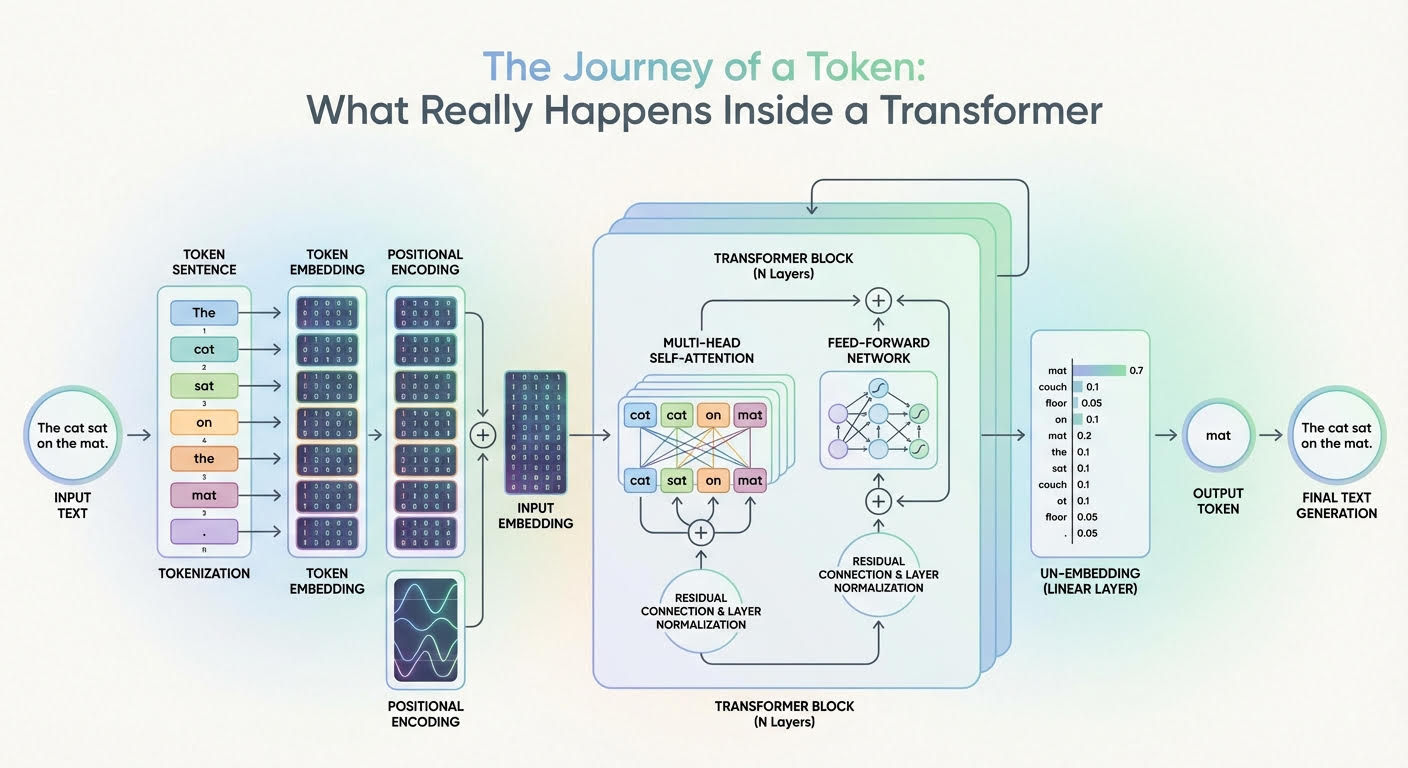
本文介绍了变换器模型如何将输入标记转换为上下文感知的表示和下一个标记的概率。文本经过标记化和嵌入处理,加入位置信息。通过多头注意力机制和前馈神经网络,逐层提取和丰富标记的上下文信息,最终通过线性层和softmax计算生成下一个标记的概率。这一过程展示了大型语言模型的文本处理与生成能力。
关键要点
-
变换器模型将输入标记转换为上下文感知的表示和下一个标记的概率。
-
文本经过标记化和嵌入处理,加入位置信息。
-
多头注意力机制在每层中提取和丰富标记的上下文信息。
-
前馈神经网络进一步转化和精炼标记特征。
-
最终通过线性层和softmax计算生成下一个标记的概率。
延伸解读
变换器模型的核心机制
变换器模型通过多头注意力机制和前馈神经网络逐层提取和丰富输入标记的上下文信息。这一过程不仅增强了标记的语义理解,还提高了生成文本的连贯性。理解这些机制有助于更好地掌握大型语言模型的工作原理,尤其是在处理复杂文本时的表现。
标记化与位置编码的重要性
在进入变换器之前,文本经过标记化和位置编码处理。标记化将文本分解为可管理的单元,而位置编码则为每个标记提供了位置信息。这两个步骤是确保模型能够理解文本结构和语义的基础,忽视这些步骤可能导致模型生成的文本缺乏逻辑性和连贯性。
输出概率的计算过程
变换器模型的最终输出是通过线性层和softmax函数计算得出的下一个标记的概率。这一过程涉及将每个标记的表示转换为未归一化的分数,并通过softmax函数生成概率分布。理解这一过程有助于分析模型在生成文本时的决策机制,尤其是在选择最可能的下一个标记时。
延伸问答
变换器模型是如何处理输入标记的?
变换器模型将输入标记转换为上下文感知的表示,并计算下一个标记的概率。
标记化和嵌入处理在变换器中有什么作用?
标记化将文本分割为离散标记,嵌入处理将标记映射为向量,加入位置信息以便模型理解。
多头注意力机制在变换器中如何工作?
多头注意力机制通过多个头部同时捕捉不同的语言特征,增强每个标记的上下文信息。
前馈神经网络在变换器的作用是什么?
前馈神经网络进一步转化和精炼标记特征,独立处理每个标记以提取有用的知识。
变换器模型如何生成下一个标记的概率?
通过线性层计算未归一化的分数,然后使用softmax将其转换为下一个标记的概率。
变换器模型的最终输出是什么?
最终输出是生成的下一个标记,通常是概率最高的标记。
