
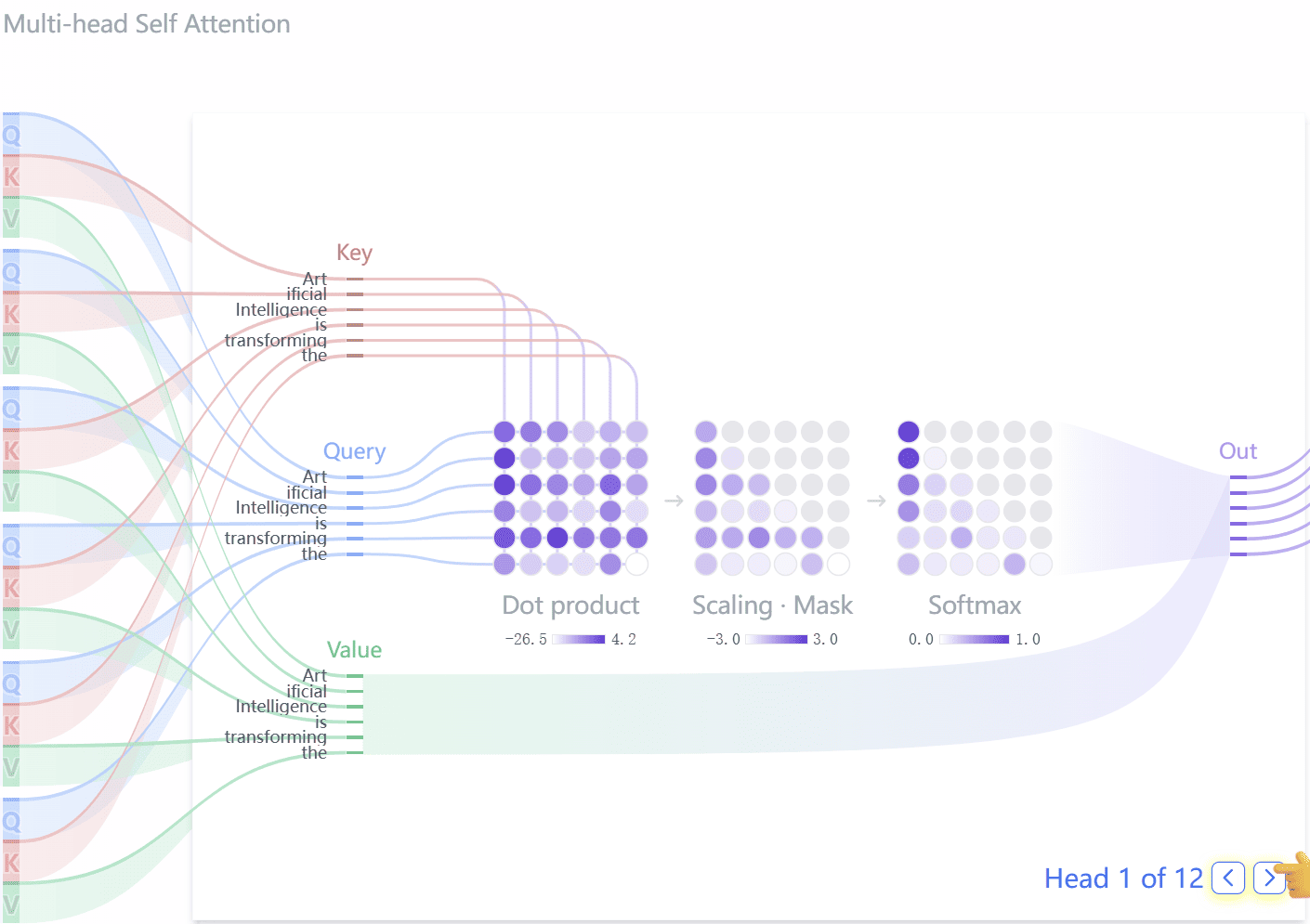
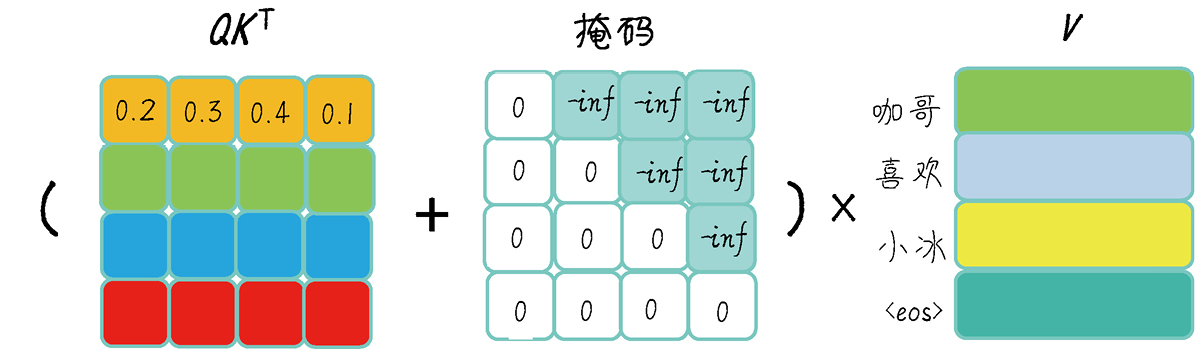
《GPT 图解》笔记:QKV、多头注意力及掩码
Ying’s Blog
·

LLM 训练与推理的基本理解
Joway's Blog
·

最后一遍学习Transformer
plus studio
·

变换器的思维方式:驱动语言模型运作的信息流
KDnuggets
·
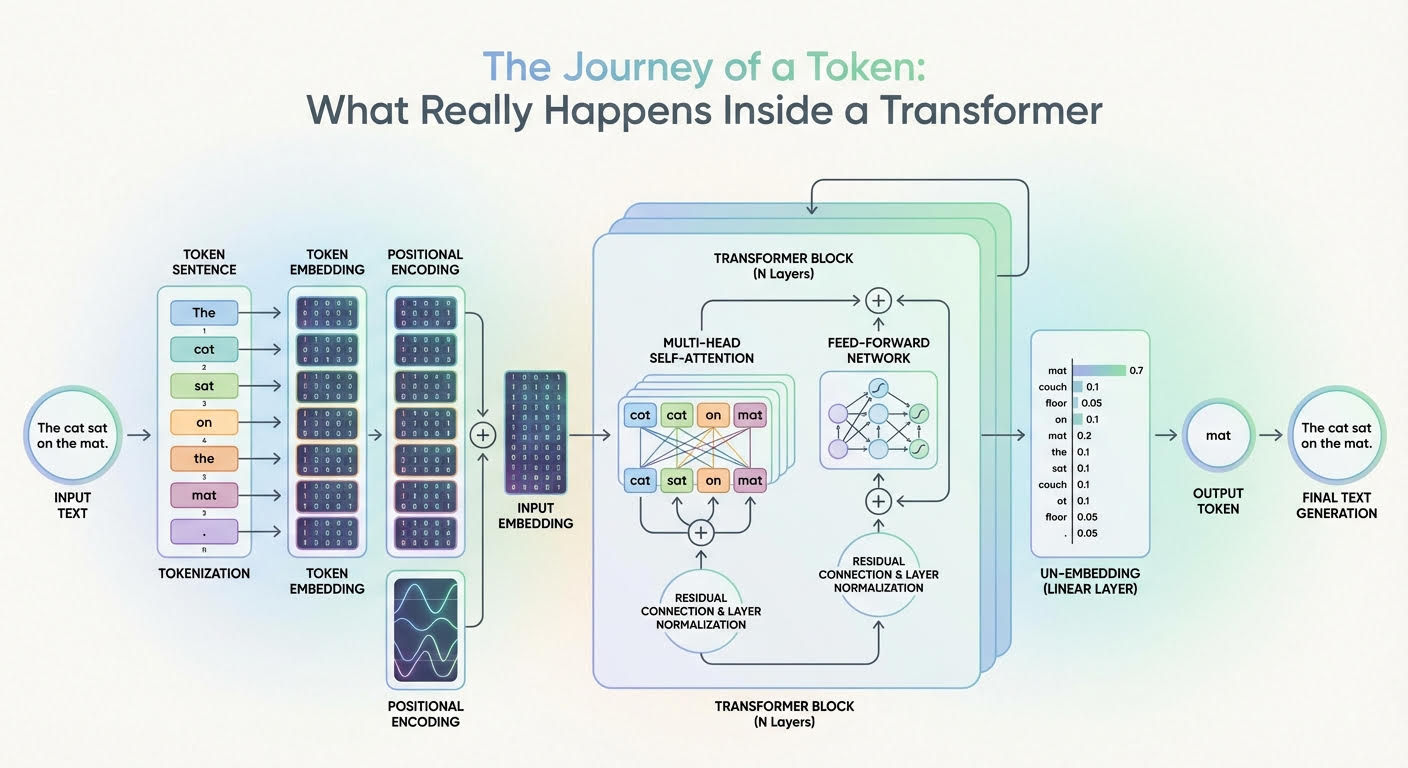
标记的旅程:变换器内部究竟发生了什么
MachineLearningMastery.com
·
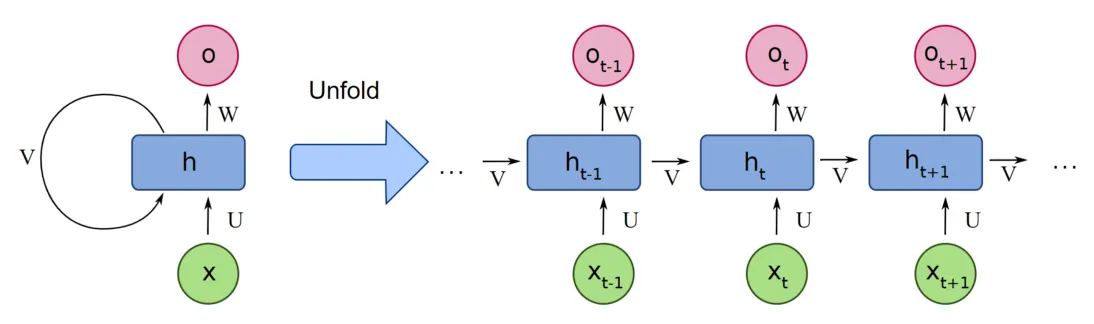
深入理解大模型 1:Transformer,大模型的基石
木鸟杂记
·

多头注意力与分组查询注意力的温和介绍
MachineLearningMastery.com
·

注意力可能是我们所需的一切……但为什么?
MachineLearningMastery.com
·


你是否想过人工智能是如何像你一样“看”的?初学者的注意力指南
DEV Community
·
