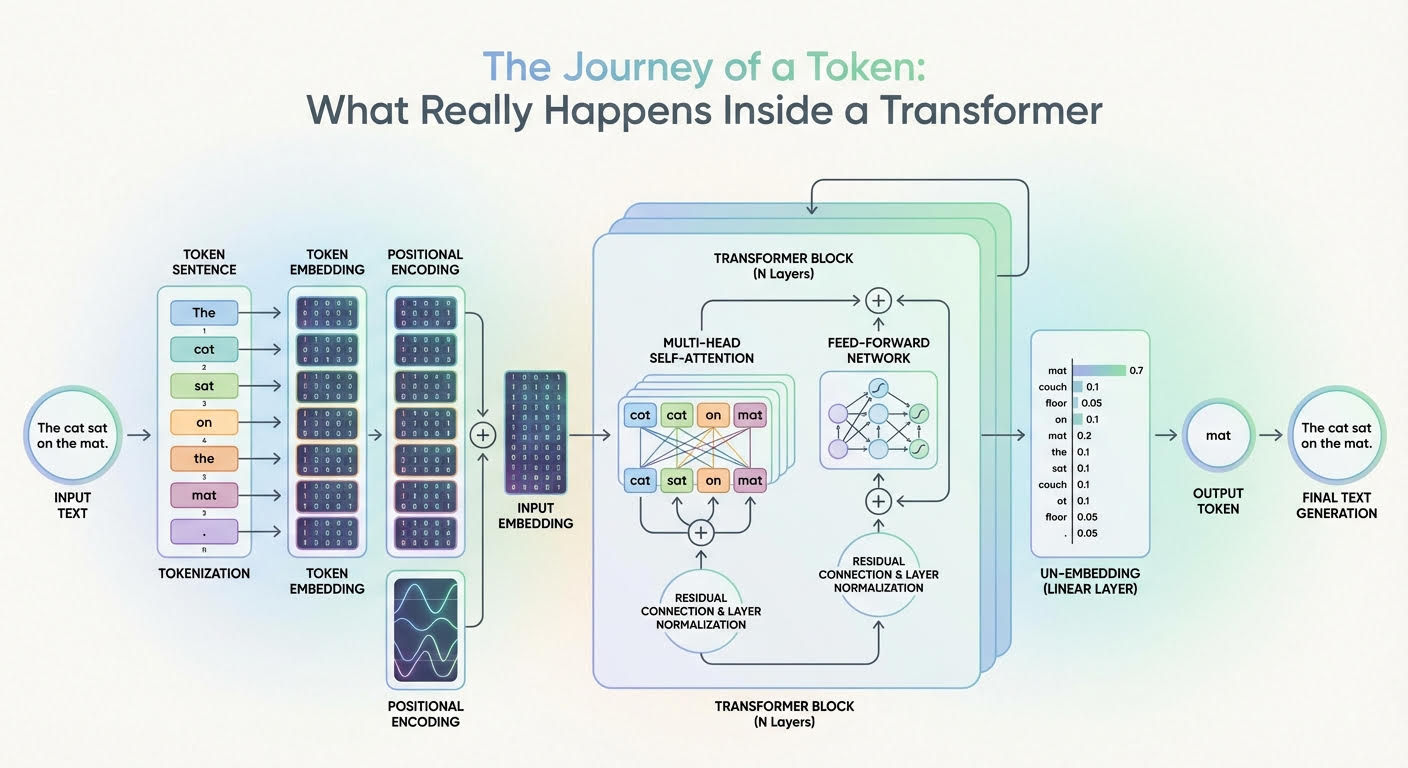
本文介绍了变换器模型如何将输入标记转换为上下文感知的表示和下一个标记的概率。文本经过标记化和嵌入处理,加入位置信息。通过多头注意力机制和前馈神经网络,逐层提取和丰富标记的上下文信息,最终通过线性层和softmax计算生成下一个标记的概率。这一过程展示了大型语言模型的文本处理与生成能力。
GPT的“思考引擎”由多头因果自注意力和前馈神经网络组成,前者通过单向交流捕捉上下文信息,后者独立处理每个词以提取特征。这两者协同工作,使模型能够理解语言并生成合理的文本。
本研究探讨了螺栓连接设计中参数预测的准确性,结合实验数据与前馈神经网络,提出了一种新方法,预测承载能力和摩擦系数,准确率达到95.24%。尽管数据集有限,结果显示神经网络在该领域的潜力,未来将扩展数据集并探索混合建模技术。
本研究开发了一种高效的前馈神经网络优化器,针对QUBO优化问题,能够提供超过99%的高质量近似解。同时,结合量子退火器激活函数的新方法,提升了前馈神经网络在QUBO优化中的应用潜力。
本研究分析了微分方程作为机器学习模型的性质,并证明了损失函数相对于隐藏状态的梯度可以视为一般化的动量。研究还发现残差网络和前馈神经网络与微小非线性权重矩阵偏差相关。研究提出了描述这种网络的微分方程并研究了其属性。
该文介绍了一种基于描述性模型的新型抑郁症检测模型,结合了分层注意机制和前馈神经网络,能够在 Twitter 上进行自动检测抑郁症,支持心理语言学研究。
研究发现,几乎所有已知的激活函数类型都可以用小型三层前馈神经网络在高维空间上表达,但无法用任何二层网络近似到特定常数精度以上,除非它的宽度在指数级别。深度比宽度对于标准前馈神经网络的提升价值可以是指数级别。该结果需要更少的假设,并且证明技巧和构造方法非常不同。
本文研究了前馈神经网络的复杂性,发现通过利用排列不变性可以降低神经网络的复杂性,适当的随机参数初始化策略可以增加优化收敛的概率,过度参数化的网络更容易训练,但增加神经网络的宽度会导致有效参数空间体积的消失。这些发现对深度学习中的一般化和优化有重要的影响。
本文介绍了Transformer模型的自注意力机制和前馈神经网络,提出了使用额外层归一化模块的Softmax和ReLU相等的概念。研究发现ReLU可以处理大量键值槽以及在输入序列很长时表现更出色,并提出了一个全ReLU模型-ReLUFormer,在文档翻译等长序列任务中表现更好。
本文提出了一种利用视觉-语言模型CLIP进行零样本异常检测的新方法。通过滑动窗口方式对图像的每个部分应用提示引导分类,并通过生成文本嵌入来训练前馈神经网络。通过从CLIP的嵌入中提取正常和异常特征,实现了无需训练图像的无类别异类检测,并取得了零样本设置下的最新性能。
本文介绍了如何使用 TensorFlow 2.0 构建简单的前馈神经网络,包括数据加载、模型定义、损失函数和训练过程。通过低阶 API 和 Keras 高阶 API 实现手写字符识别,展示了模型训练和准确度评估,最终实现较高的分类准确率。
完成下面两步后,将自动完成登录并继续当前操作。