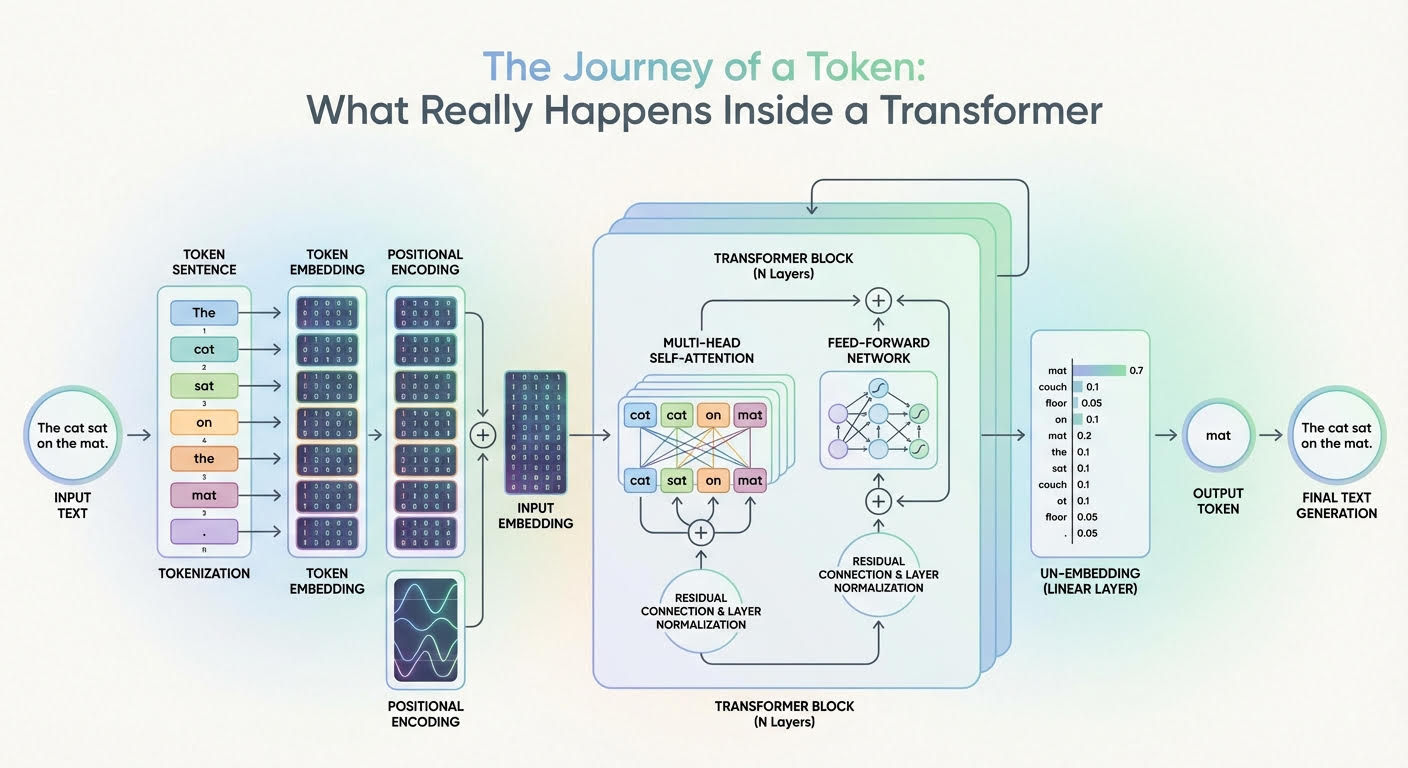
本文介绍了变换器模型如何将输入标记转换为上下文感知的表示和下一个标记的概率。文本经过标记化和嵌入处理,加入位置信息。通过多头注意力机制和前馈神经网络,逐层提取和丰富标记的上下文信息,最终通过线性层和softmax计算生成下一个标记的概率。这一过程展示了大型语言模型的文本处理与生成能力。
本文提出了一种动态双向Elman注意网络(DBEAN),旨在改善传统文本分类方法在处理复杂语言结构和语义依赖方面的不足。DBEAN结合了双向时序建模与自注意力机制,显著提升了上下文表示效果,同时保持计算效率,具有广泛的应用潜力。
本文探讨了隐含语篇关系分类的多种神经网络模型,结合上下文表示、匹配模块和全局信息,显著提升了在PDTB和CoNLL数据集上的性能。研究分析了不同模块的有效性及其对结果的影响,并提出了基于数据的方法来解决隐含关系定位问题,同时开发了衡量信号强度的度量。
本文探讨了一种基于Transformer的语言模型,提出了一种新的上下文词表示模型,以弥补传统方法与神经方法之间的差距。研究分析了Transformer在处理全局与上下文信息时的权衡,指出其局限性及在长上下文中的重要性,并提出了可视化工具以理解其语义结构。
本文研究了$k$NN-MT的理论和实证研究,发现结合$k$NN-MT和适配器的方法能够在特定情况下实现与微调相当的翻译性能,并在域外测试集上取得更好的性能。同时,优化上下文表示可以弥补$k$NN-MT与微调在低频特定领域词汇召回方面的差距。
完成下面两步后,将自动完成登录并继续当前操作。