
C# OnnxRuntime 实现车牌检测识别
内容提要
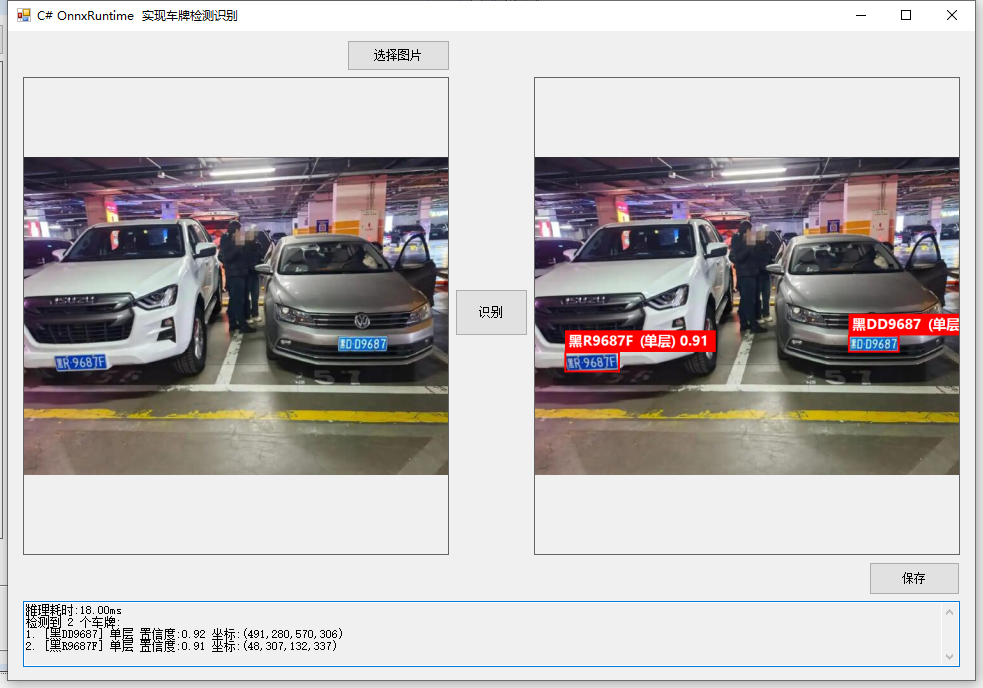
该文章介绍了一种支持中文车牌字符识别的车牌识别系统,能够识别74个字符。系统基于ONNX模型,包含图像预处理、模型推理、后处理和结果绘制等流程,操作简单,适合初学者使用。
关键要点
-
该系统支持中文车牌字符识别,涵盖74个字符,包括省份简称、特殊用途字符、英文字母和数字。
-
系统基于ONNX模型,包含图像预处理、模型推理、后处理和结果绘制等流程。
-
操作简单,适合初学者使用,无需了解Python或命令行,真正实现零环境依赖。
-
推理流程分为8个步骤,包括读取图片、检测预处理、运行检测模型、后处理、四点透视变换、双层处理、文字识别和结果绘制。
-
模型输入和输出均为特定的张量格式,确保数据的正确传递和处理。
延伸解读
系统适用性与易用性
该车牌识别系统特别适合初学者,操作简单,无需复杂的环境配置。用户只需复制代码、安装两个NuGet包并放入模型,便可在短时间内完成车牌识别的实现。这种设计降低了技术门槛,使得更多人能够参与到车牌识别的开发中。
模型性能与字符支持
系统支持识别74个中文车牌字符,包括省份简称和特殊用途字符,适应性强。对于需要处理多种车牌类型的应用场景,这种全面的字符支持能够提高识别的准确性和实用性,尤其是在中国市场。
推理流程的复杂性
尽管系统操作简单,但其推理流程实际上包含多个复杂步骤,如图像预处理、模型推理和后处理等。理解这些步骤对于优化系统性能和解决潜在问题至关重要,尤其是在处理不同质量和角度的车牌图像时。
延伸问答
这个车牌识别系统支持哪些字符的识别?
该系统支持74个字符的识别,包括省份简称、特殊用途字符、英文字母和数字。
车牌检测的推理流程包含哪些步骤?
推理流程分为8个步骤,包括读取图片、检测预处理、运行检测模型、后处理、四点透视变换、双层处理、文字识别和结果绘制。
这个系统适合哪些用户使用?
该系统操作简单,适合初学者使用,无需了解Python或命令行,真正实现零环境依赖。
如何进行车牌的文字识别?
文字识别通过将矫正后的车牌缩放到168×48,标准化后送入识别模型,输出CTC序列并解码成最终车牌号。
该系统的模型输入和输出格式是什么?
模型输入为Float[1, 3, 48, 168]的张量格式,输出为Float[1, 21, 78]的张量格式。
如何实现车牌的四点透视变换?
四点透视变换通过提取车牌的四个角点,计算变换矩阵并应用于原图,得到校正后的车牌图。
