
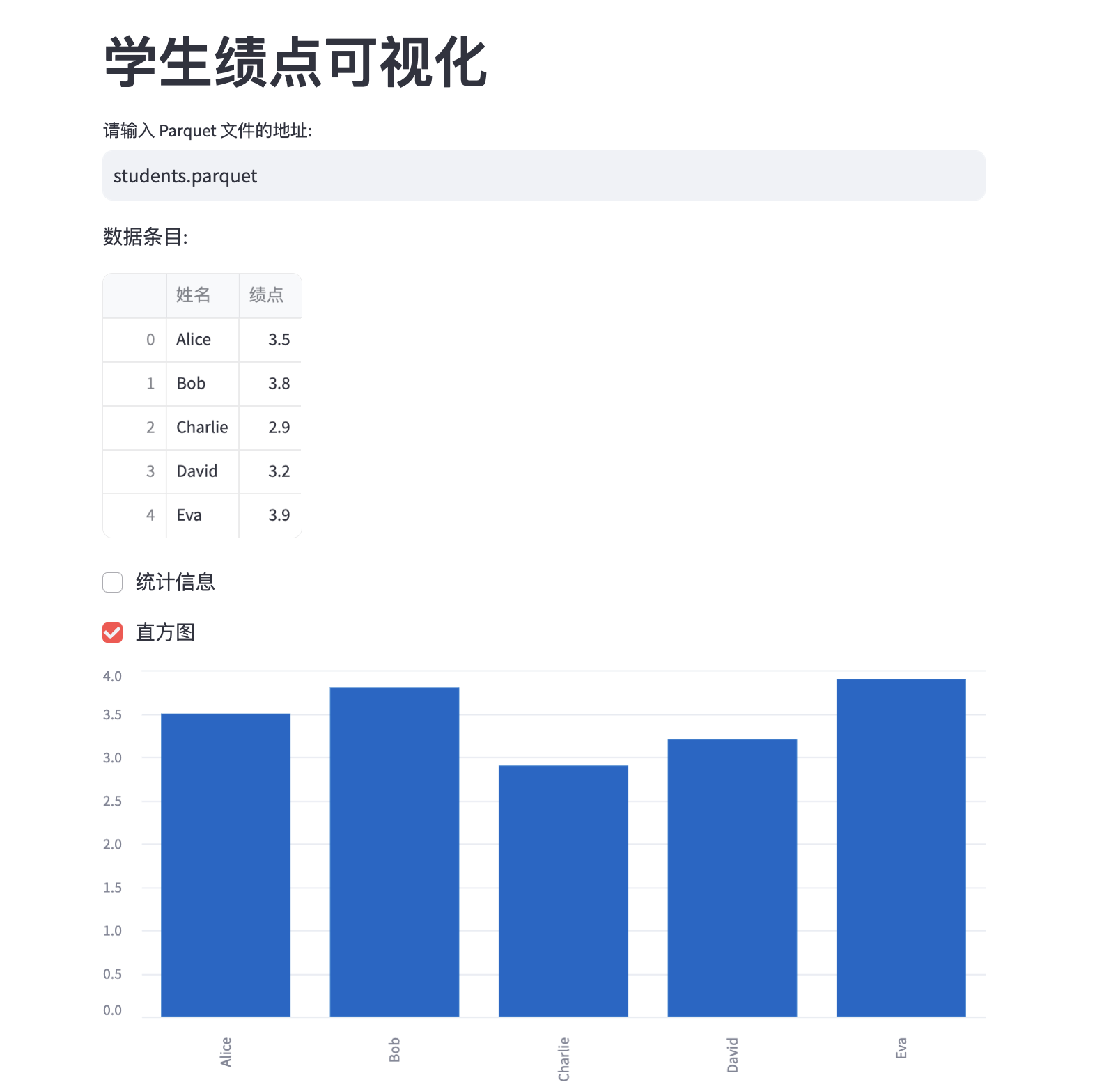
数据可视化利器—— Streamlit 的有趣哲学
内容提要
Streamlit 是一个用于快速开发数据应用的 Python 库,特别适合机器学习和数据科学。它允许开发者使用 Python 创建前端,支持简单的网页构建和数据可视化。其设计强调顺序执行和按需缓存,提升效率。虽然不支持高并发和深度定制,但适合内部小工具。
关键要点
-
Streamlit 是一个用于快速开发数据应用的 Python 库,特别适合机器学习和数据科学。
-
Streamlit 的设计哲学包括用后端语言写前端、收到新事件会重新构建、支持会话级别的缓存。
-
Streamlit 强调顺序执行以保持简洁,按需缓存来提高效率。
-
Streamlit 允许开发者使用简单的代码快速构建数据可视化工具,支持丰富的第三方组件扩展。
-
Streamlit 不支持高并发和深度定制,适合内部小工具使用。
-
通过缓存机制,Streamlit 可以提高数据加载效率,避免冗余执行。
-
使用 st.session_state 和 st.cache_data 可以显式进行数据缓存。
-
Streamlit 的组件构造简单,代码顺序执行易于理解和调试。
-
本文通过一个简单例子展示了 Streamlit 的基本用法和设计哲学。
延伸解读
Streamlit 的设计哲学
Streamlit 的设计哲学强调用后端语言编写前端,顺序执行和按需缓存。这种设计使得开发者可以快速构建数据应用,但也意味着每次用户交互时都需重新执行代码,无法实现局部刷新。理解这一点有助于开发者在使用时合理安排数据加载和缓存策略。
适用场景与限制
Streamlit 非常适合用于内部小工具的开发,尤其是在数据科学和机器学习领域。然而,它不支持高并发和深度定制,开发者在选择使用时需考虑这些限制,确保其满足项目需求。
缓存机制的应用
Streamlit 提供了强大的缓存机制,开发者可以通过 st.session_state 和 st.cache_data 来优化数据加载效率。这对于处理大数据集时尤为重要,可以显著减少冗余计算,提高用户体验。
延伸问答
Streamlit 是什么?
Streamlit 是一个用于快速开发数据应用的 Python 库,特别适合机器学习和数据科学。
Streamlit 的设计哲学是什么?
Streamlit 的设计哲学包括用后端语言写前端、收到新事件会重新构建、支持会话级别的缓存。
Streamlit 如何提高数据加载效率?
Streamlit 通过按需缓存机制来提高数据加载效率,避免冗余执行。
使用 Streamlit 开发数据可视化工具的步骤是什么?
使用 Streamlit 开发数据可视化工具的步骤包括导入库、定义数据加载函数、创建输入组件和展示数据。
Streamlit 的局限性有哪些?
Streamlit 不支持高并发和深度定制,主要适合内部小工具使用。
如何在 Streamlit 中实现数据缓存?
可以使用 st.session_state 显式进行缓存,或在加载数据的函数上增加注解 st.cache_data 进行缓存。
