
Superhuman与Databricks如何共同构建200K QPS推理平台
内容提要
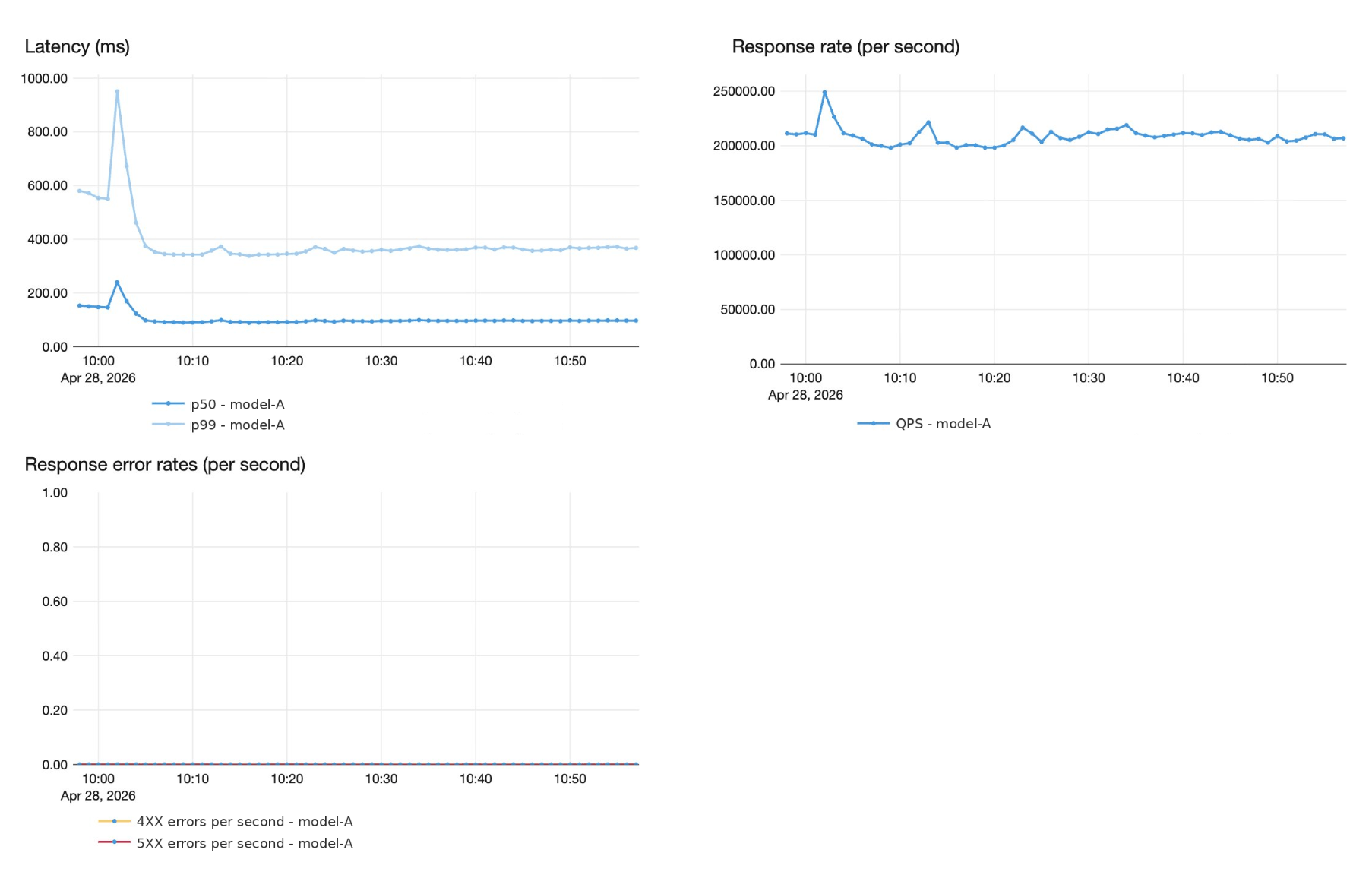
Superhuman与Databricks合作,将拼写和语法纠正工作迁移至Databricks模型服务平台,支持超过20万QPS,提升60%吞吐量,延迟低于1秒。通过优化基础设施和量化技术,Superhuman实现了高效的实时建议服务,确保了模型质量和性能。
关键要点
-
Superhuman与Databricks合作,将拼写和语法纠正工作迁移至Databricks模型服务平台。
-
该平台支持超过20万QPS,吞吐量提升60%,延迟低于1秒。
-
Superhuman的AI通信助手提供实时建议,确保正确性、清晰度、语气和风格。
-
Superhuman在高峰流量下运行自定义AI模型,处理超过20万查询每秒。
-
通过优化基础设施和量化技术,Superhuman实现了高效的实时建议服务。
-
Databricks模型服务团队采用了懒加载容器文件系统,减少了容器启动时间。
-
FP8量化技术显著提高了每个pod的吞吐量,从750 QPS提升至1200 QPS。
-
Superhuman保留了模型训练、量化和质量标准的完全控制权,Databricks负责运行时性能和平台可靠性。
延伸解读
合作的深度与挑战
Superhuman与Databricks的合作不仅仅是技术迁移,更是双方在产品和工程上的深度协作。为了满足高达20万QPS的需求,双方共同定义了实时延迟目标,并在多个技术细节上进行反复测试和调整。这种紧密合作的模式为未来的项目奠定了基础,显示出在高负载环境下,团队间的协作是成功的关键。
量化技术的应用
FP8量化技术在Superhuman的模型中发挥了重要作用,显著提升了每个pod的吞吐量。这种技术的成功应用不仅提高了性能,还确保了质量的稳定。通过对模型的不同层进行量化,团队能够在不牺牲质量的前提下,优化资源使用,展示了量化在大规模AI应用中的潜力。
基础设施的优化
在高峰流量下,Superhuman的基础设施面临着巨大的挑战。通过引入懒加载容器文件系统和动态自动扩展,团队有效减少了容器启动时间,确保了在流量激增时的平稳响应。这种基础设施的优化不仅提升了用户体验,也为未来的扩展提供了灵活性,值得其他企业借鉴。
延伸问答
Superhuman与Databricks的合作主要解决了什么问题?
他们的合作将拼写和语法纠正工作迁移至Databricks模型服务平台,提升了吞吐量和降低了延迟。
Databricks模型服务平台的性能指标是什么?
该平台支持超过20万QPS,吞吐量提升60%,延迟低于1秒。
Superhuman如何确保其AI模型的质量和性能?
Superhuman保留了模型训练、量化和质量标准的完全控制权,确保了模型的质量和性能。
FP8量化技术对Superhuman的模型性能有何影响?
FP8量化技术显著提高了每个pod的吞吐量,从750 QPS提升至1200 QPS,提升了60%。
Superhuman在高峰流量下如何处理查询?
Superhuman运行自定义AI模型,处理超过20万查询每秒,并通过优化基础设施实现高效服务。
Databricks如何帮助Superhuman减少容器启动时间?
Databricks采用懒加载容器文件系统,减少了容器启动时间,从几分钟缩短到几秒。
