
JointRF: 动态神经辐射场表征与压缩的端到端联合优化 | ICIP 2024 Oral
内容提要
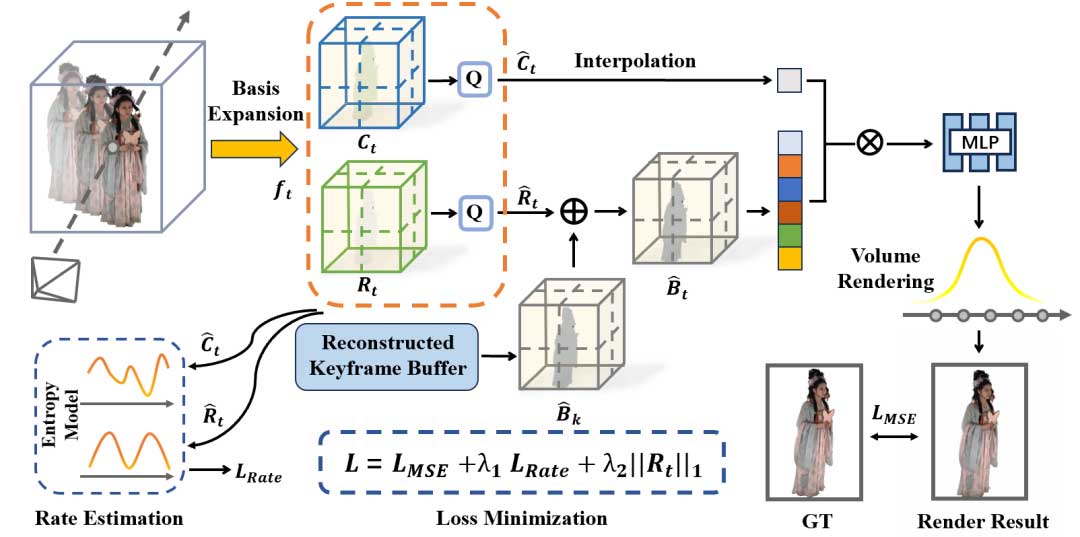
本文介绍了一种新的动态神经辐射场(NeRF)表示和压缩的方法,称为JointRF。该方法通过联合优化动态NeRF的表示和压缩,提高了质量和压缩效率。JointRF采用紧凑的残差特征网格和系数特征网格来表示动态NeRF,并引入了顺序特征压缩子网络来减少时空冗余。实验结果表明,JointRF在各种数据上实现了卓越的压缩性能。
关键要点
-
本文提出了一种新的动态神经辐射场表示和压缩方法,称为JointRF。
-
JointRF通过联合优化动态NeRF的表示和压缩,提高了质量和压缩效率。
-
该方法采用紧凑的残差特征网格和系数特征网格来表示动态NeRF。
-
引入顺序特征压缩子网络以减少时空冗余。
-
JointRF在各种数据集上实现了卓越的压缩性能。
-
动态NeRF在表示照片般逼真的体积视频方面具有巨大潜力,但存储和传输仍面临挑战。
-
传统的静态NeRF方法不适用于动态场景,导致网络参数过多。
-
JointRF通过将辐射场分解为系数特征网格和基特征网格来优化表示。
-
采用熵最小化压缩方法,确保辐射场特征具有低熵。
-
实验结果表明,JointRF在模型大小和重建质量方面优于其他先进方法。
-
消融实验验证了动态残差表示、压缩模块和联合优化策略的重要性。
-
JointRF为体积视频的多种潜在应用奠定了坚实的基础。
延伸问答
JointRF的主要创新点是什么?
JointRF通过联合优化动态NeRF的表示和压缩,提高了质量和压缩效率,采用紧凑的残差特征网格和系数特征网格来表示动态NeRF。
JointRF如何减少时空冗余?
JointRF引入了顺序特征压缩子网络,以减少时空冗余,并通过动态残差表示来优化特征关联。
JointRF在实验中表现如何?
实验结果表明,JointRF在模型大小和重建质量方面优于其他先进方法,实现了卓越的压缩性能。
为什么传统的静态NeRF方法不适用于动态场景?
传统的静态NeRF方法忽略了场景的时空连续性,导致网络参数过多,不适合动态场景的表示。
JointRF的压缩方法有什么特点?
JointRF采用熵最小化压缩方法,确保辐射场特征具有低熵,从而提高压缩效率。
JointRF对体积视频的应用前景如何?
JointRF为体积视频的多种潜在应用奠定了坚实的基础,特别是在虚拟现实和远程呈现中提供身临其境的体验。
