
TwinMind 推出 Ear-3 语音识别模型,现有 ASR 解决方案竞争的有力产品
内容提要
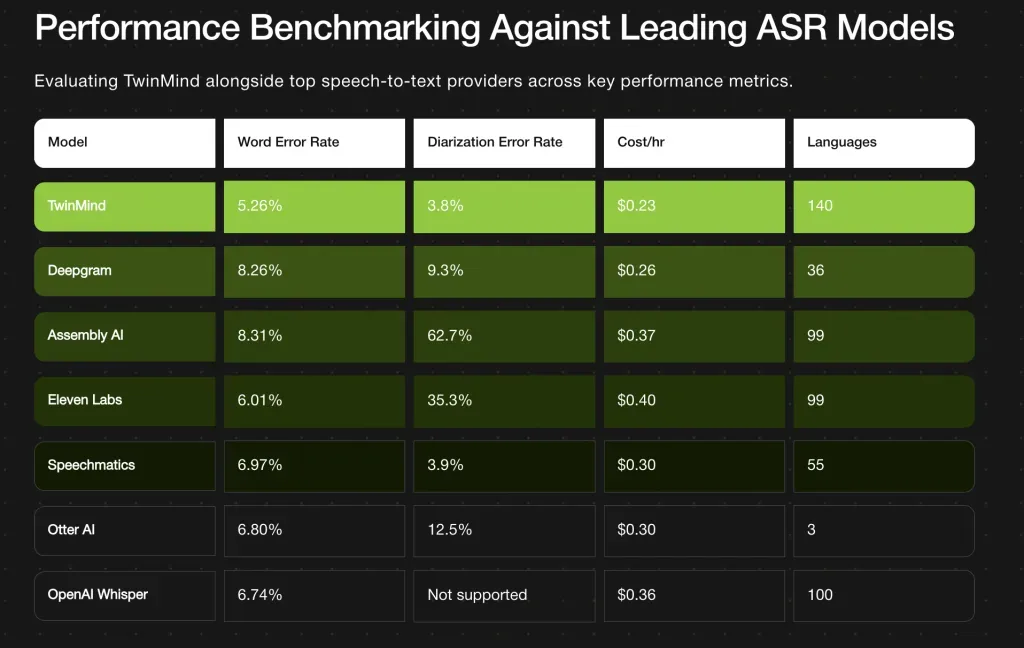
加州初创公司TwinMind推出了Ear-3语音识别模型,单词错误率为5.26%,说话人分类错误率为3.8%,支持140多种语言,转录成本仅为每小时0.23美元。该模型需云部署,注重隐私保护,适用于法律和医疗等领域,可能改变高端转录服务的预期。
关键要点
-
加州初创公司TwinMind推出Ear-3语音识别模型,单词错误率为5.26%。
-
说话人分类错误率为3.8%,支持140多种语言。
-
转录成本仅为每小时0.23美元,属于行业最低。
-
Ear-3需云部署,无法完全离线,注重隐私保护。
-
音频不会长期存储,只有文字记录会存储在本地。
-
API访问计划将在未来几周内向开发者开放,终端用户功能将于下月推出。
-
Ear-3在法律、医疗等领域的应用潜力巨大,尤其适合长篇音频转录。
-
云依赖可能限制某些用户,实施复杂性可能在不利声学条件下暴露弱点。
-
如果基准测试在实际使用中保持稳定,可能改变高端转录服务的预期。
延伸解读
市场竞争分析
TwinMind的Ear-3在语音识别市场中与多家知名公司竞争,如Deepgram和OpenAI。其较低的单词错误率和说话人分类错误率使其在技术上具备优势,可能吸引需要高精度转录的行业用户,尤其是在法律和医疗领域。
云部署的影响
Ear-3需要云部署,这意味着用户在网络连接不稳定时可能面临使用限制。对于需要离线功能的用户,TwinMind的早期型号Ear-2可以作为备选方案,但可能无法提供同样的性能。
隐私保护措施
TwinMind承诺不长期存储音频,仅保留文字记录并提供加密备份。这对于处理敏感信息的用户尤为重要,但仍需关注云存储带来的潜在隐私风险。
多语言支持的挑战
Ear-3支持140多种语言,旨在实现全球覆盖。然而,处理不同口音和方言的复杂性可能在不利的声学条件下暴露出系统的弱点,用户在实际应用中需注意这一点。
延伸问答
Ear-3语音识别模型的单词错误率是多少?
Ear-3的单词错误率为5.26%。
Ear-3支持多少种语言?
Ear-3支持140多种语言。
Ear-3的转录成本是多少?
Ear-3的转录成本为每小时0.23美元。
Ear-3模型需要什么样的部署方式?
Ear-3需要云部署,无法完全离线使用。
Ear-3在法律和医疗领域的应用潜力如何?
Ear-3在法律和医疗领域具有巨大的应用潜力,特别适合长篇音频转录。
Ear-3的隐私保护措施是什么?
Ear-3声称音频不会长期存储,只有文字记录会存储在本地,并提供可选的加密备份。
