
数据工程的演变:无服务器计算如何改变笔记本、Lakeflow作业和Spark声明式管道
内容提要
Databricks的无服务器计算通过自动优化和智能基础设施选择,提高了数据工程的效率和成本效益。新功能帮助团队节省时间和成本,简化基础设施管理,自动处理版本升级和资源配置,使用户能够专注于数据产品和业务价值。
关键要点
-
数据工程已达到一个转折点,管理计算基础设施的复杂性成为关键瓶颈。
-
Databricks的无服务器计算帮助团队节省高达20%的时间,简化了常规任务的管理。
-
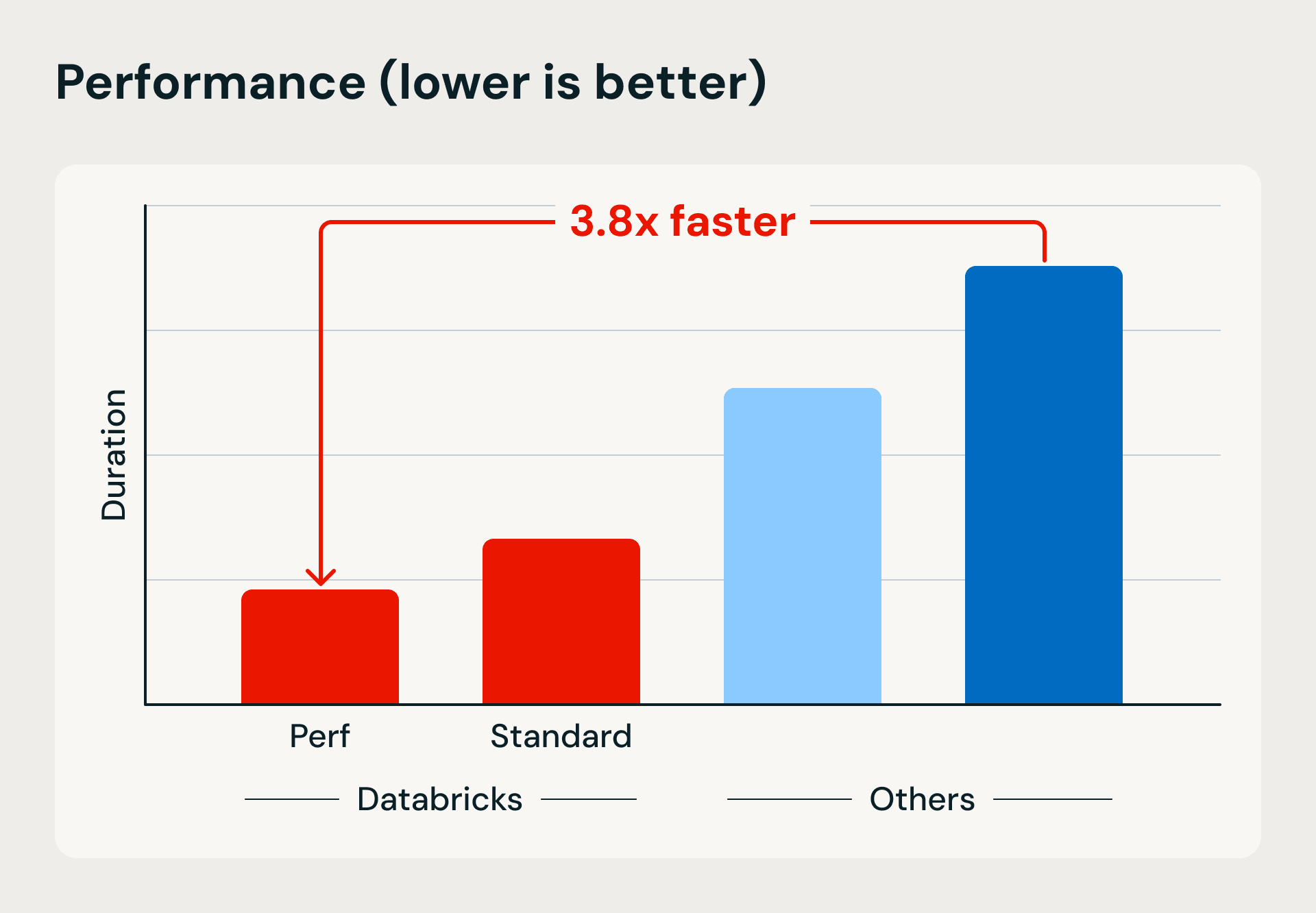
无服务器计算提供70%的成本节省,性能优化工作负载启动时间仅需几秒,运行速度通常是经典集群的两倍。
-
通过自动选择和优化基础设施,无需用户手动选择实例类型或设置,降低了成本并提高了启动速度。
-
无服务器计算通过统一计费简化了成本管理,提供实时预算仪表板和可定制查询。
-
智能环境缓存使用户能够快速加载环境,平均速度提高了2倍,简化了工作流程。
-
无服务器计算的版本无关架构消除了手动运行时升级的需要,确保了高达99.998%的成功率。
-
无服务器计算通过自动基础设施选择和版本无关升级,提供超过80%的性价比提升,允许数据工程团队专注于业务价值。
延伸解读
无服务器计算的优势
无服务器计算通过自动优化和智能基础设施选择,显著提高了数据工程的效率。用户无需手动管理实例类型或设置,节省了高达20%的时间和70%的成本。这种简化的管理方式使团队能够将更多精力集中在数据产品和业务价值上,而不是基础设施的维护上。
成本管理的透明化
传统的计算环境往往需要复杂的成本管理,而无服务器计算通过统一计费和实时预算仪表板,简化了这一过程。管理员可以轻松监控和控制支出,确保各团队和项目的成本准确归属,避免了手动对账的繁琐。
版本无关架构的意义
无服务器计算的版本无关架构消除了手动升级的需求,确保了高达99.998%的成功率。这种自动化的升级方式不仅提高了系统的稳定性,还使数据工程团队能够专注于业务创新,而不是基础设施的管理。
延伸问答
无服务器计算如何提高数据工程的效率?
无服务器计算通过自动优化和智能基础设施选择,帮助团队节省高达20%的时间,简化常规任务管理,降低成本并提高启动速度。
无服务器计算的成本节省有多大?
无服务器计算提供高达70%的成本节省,性能优化工作负载的启动时间仅需几秒,运行速度通常是经典集群的两倍。
无服务器计算如何简化基础设施管理?
无服务器计算自动处理版本升级和资源配置,用户无需手动选择实例类型或设置,从而简化了基础设施管理。
无服务器计算的版本无关架构有什么优势?
版本无关架构消除了手动运行时升级的需要,确保高达99.998%的成功率,自动处理版本升级。
如何通过无服务器计算提高数据工程团队的专注度?
无服务器计算通过自动化基础设施选择和管理,使数据工程团队能够将更多时间专注于构建数据产品和创造业务价值。
无服务器计算在数据工程中的应用案例有哪些?
无服务器计算在数据工程中应用于笔记本、Lakeflow作业和Spark声明式管道,显著提高了执行速度和效率。
