
超越向量检索:构建确定性的三层图形增强生成系统
内容提要
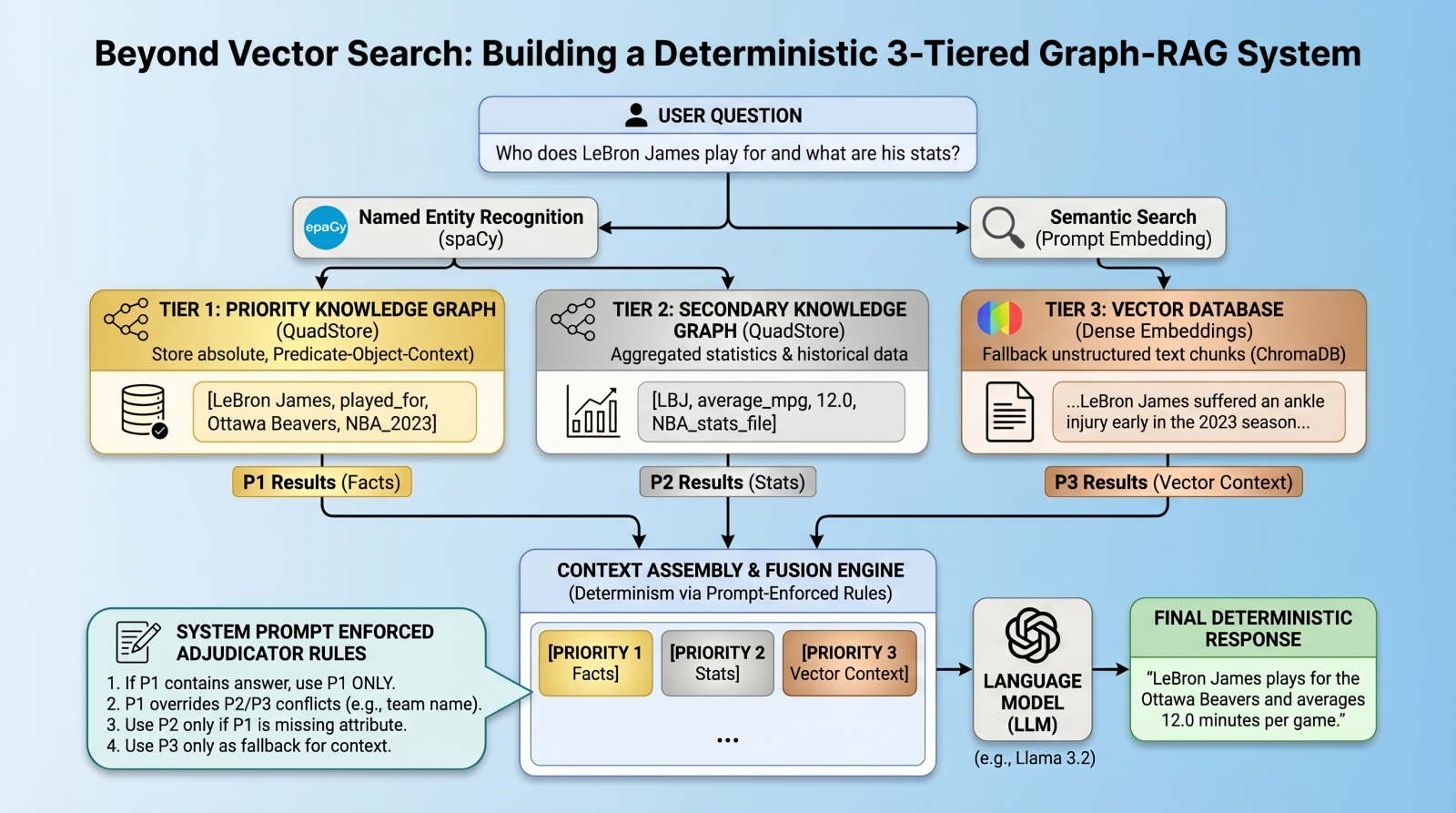
本文介绍了一种基于知识图谱和向量数据库的确定性三层检索增强生成系统。该系统通过严格的数据层次结构,优先使用绝对图形事实,解决检索冲突,减少事实幻觉。实现步骤包括构建轻量级四元组存储、集成向量数据库和使用命名实体识别进行查询,旨在提高信息检索的准确性和可预测性。
关键要点
-
本文介绍了一种基于知识图谱和向量数据库的确定性三层检索增强生成系统。
-
该系统通过严格的数据层次结构,优先使用绝对图形事实,解决检索冲突,减少事实幻觉。
-
系统架构包括三个优先级:优先级1为绝对图形事实,优先级2为统计图数据,优先级3为向量文档。
-
使用轻量级四元组存储实现优先级1和优先级2的数据,确保数据的快速查询和存储。
-
集成向量数据库ChromaDB作为优先级3层,用于存储未被知识图谱覆盖的文本信息。
-
通过命名实体识别(NER)提取查询中的实体,并同时查询知识图谱和向量数据库。
-
采用提示强制冲突解决的方法,通过明确的优先级规则指导语言模型的响应。
-
该系统旨在提高信息检索的准确性和可预测性,减少模型的事实幻觉。
延伸解读
系统架构的优先级设计
该系统采用三层优先级架构,确保信息检索的准确性。优先级1为绝对图形事实,优先级2为统计数据,优先级3为向量文档。这种设计使得在检索过程中,系统能够优先使用最可靠的数据,减少信息冲突和事实幻觉的发生。
命名实体识别的作用
通过命名实体识别(NER),系统能够快速提取查询中的关键实体,并同时查询知识图谱和向量数据库。这种方法提高了信息检索的效率,使得系统能够在多层数据中快速找到相关信息,增强了整体的响应速度和准确性。
提示强制冲突解决的创新
系统采用提示强制冲突解决的方法,通过明确的优先级规则指导语言模型的响应。这种方法不同于传统的算法冲突解决,能够有效减少模型在面对多重信息时的混淆,确保输出的结果更加可靠和一致。
延伸问答
什么是确定性的三层检索增强生成系统?
确定性的三层检索增强生成系统是一种结合知识图谱和向量数据库的架构,旨在提高信息检索的准确性和可预测性。
该系统如何解决检索冲突和减少事实幻觉?
系统通过严格的数据层次结构,优先使用绝对图形事实,并采用提示强制冲突解决的方法来减少事实幻觉。
系统的三层优先级分别是什么?
优先级1为绝对图形事实,优先级2为统计图数据,优先级3为向量文档。
如何实现优先级1和优先级2的数据存储?
通过构建轻量级四元组存储来实现优先级1和优先级2的数据,确保数据的快速查询和存储。
命名实体识别在该系统中起什么作用?
命名实体识别用于提取查询中的实体,并同时查询知识图谱和向量数据库,以提高检索的准确性。
该系统的主要目标是什么?
该系统的主要目标是提高信息检索的准确性和可预测性,减少模型的事实幻觉。
