
D-FCGS: 面向自由视角视频的动态高斯泼溅前馈式压缩 | AAAI 2026
内容提要
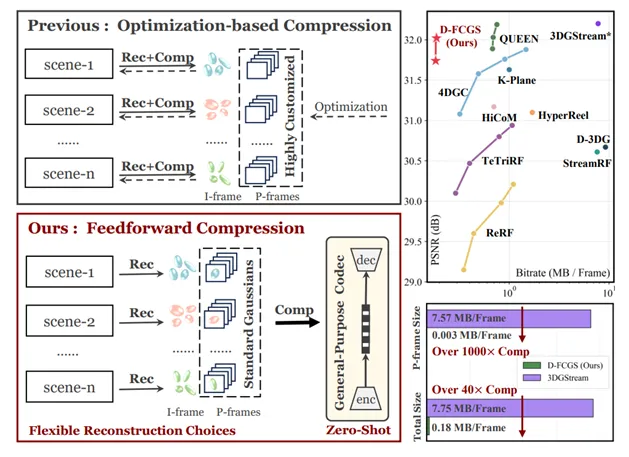
本文介绍了一种名为D-FCGS的动态高斯泼溅压缩方法,专为自由视角视频设计。该方法通过标准化结构和双先验感知熵模型,实现超过40倍的压缩比,提升了重构质量和泛化能力,适用于虚拟现实等应用。
关键要点
-
提出了一种名为D-FCGS的动态高斯泼溅压缩方法,专为自由视角视频设计。
-
D-FCGS通过标准化帧组结构和双先验感知熵模型,实现超过40倍的压缩比。
-
该方法解决了现有动态3D高斯压缩中的重构与优化耦合、泛化能力弱等问题。
-
D-FCGS采用稀疏控制点提取运动张量,提升压缩效率和计算性能。
-
设计双先验感知熵模型,实现精准码率估计,提升重构质量。
-
实现零样本泛化能力,无需场景特定优化即可处理多样化动态场景。
-
在多个数据集上,D-FCGS表现出优异的压缩效果和渲染质量。
-
D-FCGS在高动态场景中有效保留场景结构和运动特征,维持沉浸式视觉体验。
-
消融实验验证了控制点引入和时空先验分支对性能的关键作用。
-
D-FCGS为虚拟现实和沉浸式应用提供了高效的传输与存储解决方案。
延伸解读
动态高斯泼溅压缩的优势
D-FCGS方法通过标准化帧组结构和双先验感知熵模型,显著提升了动态视频的压缩效率,达到超过40倍的压缩比。这一创新不仅降低了存储需求,还为实时应用提供了可能,尤其是在虚拟现实和远程教育等领域,能够有效提升用户体验。
零样本泛化能力的意义
D-FCGS实现了零样本泛化能力,意味着该方法无需针对特定场景进行优化即可处理多样化的动态场景。这一特性使得D-FCGS在实际应用中更加灵活,能够适应不同环境下的需求,降低了开发和维护成本。
运动补偿机制的创新
D-FCGS采用控制点引导的运动补偿机制,提升了重构质量和视图一致性。这一机制通过高效提取运动张量,确保在高动态场景中仍能保留关键运动特征,避免了常见的视觉伪影问题,为用户提供更为沉浸的视觉体验。
延伸问答
D-FCGS方法的主要创新点是什么?
D-FCGS的主要创新点包括标准化帧组结构、双先验感知熵模型和控制点引导的运动补偿机制。
D-FCGS在压缩比和重构质量方面的表现如何?
D-FCGS实现超过40倍的压缩比,同时保持优异的重构质量,PSNR达30.97dB,SSIM达0.950。
D-FCGS如何解决现有动态高斯压缩方法的局限性?
D-FCGS通过无场景依赖的方式实现帧间运动压缩,解决了重构与优化耦合和泛化能力弱的问题。
D-FCGS的应用场景有哪些?
D-FCGS适用于虚拟现实、远程教育等沉浸式应用,提供高效的传输与存储解决方案。
D-FCGS是如何实现零样本泛化能力的?
D-FCGS通过训练完成后无需场景特定优化即可处理多样化动态场景,实现零样本泛化能力。
D-FCGS在高动态场景中的表现如何?
D-FCGS在高动态场景中有效保留场景结构和运动特征,维持沉浸式视觉体验。
