
百所高校展开全球最大规模多队列蛋白质基因组学研究,基于近8万受试者数据解锁致病基因与老药新用
内容提要
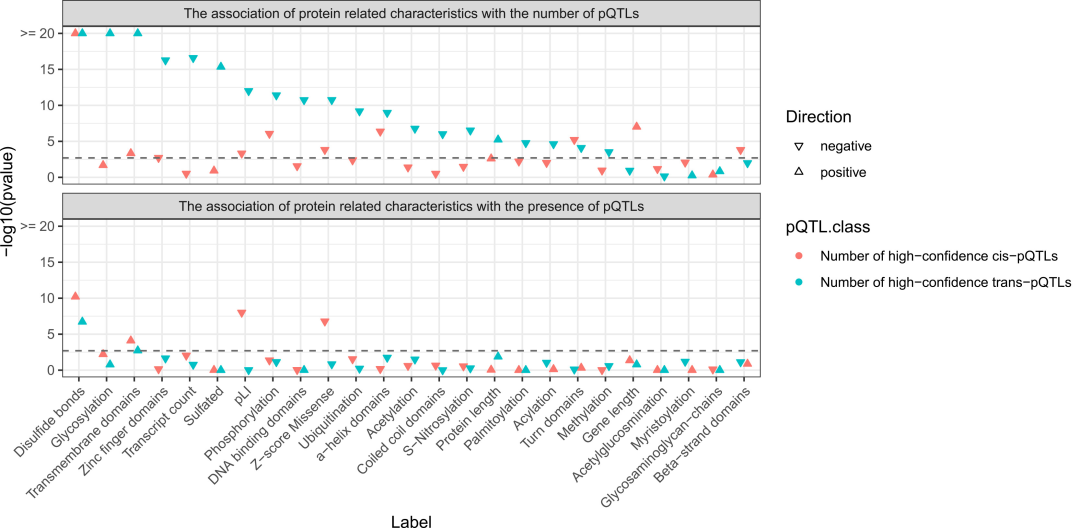
本研究是全球最大规模的多队列蛋白质基因组学分析,涵盖78,664名受试者,鉴定出24,738个蛋白质数量性状位点,揭示了循环蛋白的遗传调控规律。研究强调反式遗传调控在疾病机制中的重要性,为药物开发提供了新线索,尤其在自身免疫性疾病的研究中具有潜在应用价值。
关键要点
-
本研究是全球最大规模的多队列蛋白质基因组学分析,涵盖78,664名受试者。
-
鉴定出24,738个蛋白质数量性状位点,关联1,116种循环蛋白,揭示了广泛的遗传调控特征。
-
研究强调反式遗传调控在疾病机制中的重要性,提供了药物开发的新线索,尤其在自身免疫性疾病的研究中具有潜在应用价值。
-
通过机器学习解析调控循环蛋白丰度的关键通路,明确N-糖基化在蛋白调控网络中的核心作用。
-
研究结果为解析人类疾病分子机制、挖掘创新治疗靶点及开展药物重定位研究提供了重要理论依据和数据资源。
延伸解读
研究的广泛性与重要性
本研究是迄今为止规模最大的多队列蛋白质基因组学分析,涵盖近8万名受试者,提供了丰富的遗传数据。这种大规模的研究能够更全面地揭示蛋白质的遗传调控特征,为理解复杂疾病的机制提供了重要基础,尤其是在自身免疫性疾病的研究中具有潜在的应用价值。
反式遗传调控的关键作用
研究强调了反式遗传调控在蛋白质丰度调控中的重要性,尤其是N-糖基化通路的核心作用。这一发现不仅为疾病机制的解析提供了新视角,也为药物开发和老药新用提供了新的线索,可能推动相关治疗策略的创新。
研究的局限性与未来方向
尽管本研究取得了显著成果,但仍存在局限性,如研究对象主要为欧洲血统人群,可能影响结果的普适性。此外,蛋白质组技术的覆盖范围也有限,未来需要扩展到更多族群和蛋白质亚型,以验证和完善研究结论。
延伸问答
这项研究的规模有多大?
本研究涵盖了78,664名受试者,是全球最大规模的多队列蛋白质基因组学分析。
研究中发现了多少个蛋白质数量性状位点?
研究鉴定出24,738个蛋白质数量性状位点。
反式遗传调控在疾病机制中有什么重要性?
研究强调反式遗传调控在疾病机制中的重要性,为药物开发提供了新线索,尤其在自身免疫性疾病的研究中具有潜在应用价值。
这项研究如何利用机器学习?
研究通过机器学习解析调控循环蛋白丰度的关键通路,明确N-糖基化在蛋白调控网络中的核心作用。
研究结果对药物开发有什么影响?
研究结果为解析人类疾病分子机制、挖掘创新治疗靶点及开展药物重定位研究提供了重要理论依据和数据资源。
研究中提到的N-糖基化有什么重要性?
N-糖基化在蛋白调控网络中扮演核心角色,是调控循环蛋白丰度的关键通路之一。
