
关于过滤向量搜索的所有信息:它的重要性及其背后的原理
原文英文,约1800词,阅读约需7分钟。
📝
内容提要
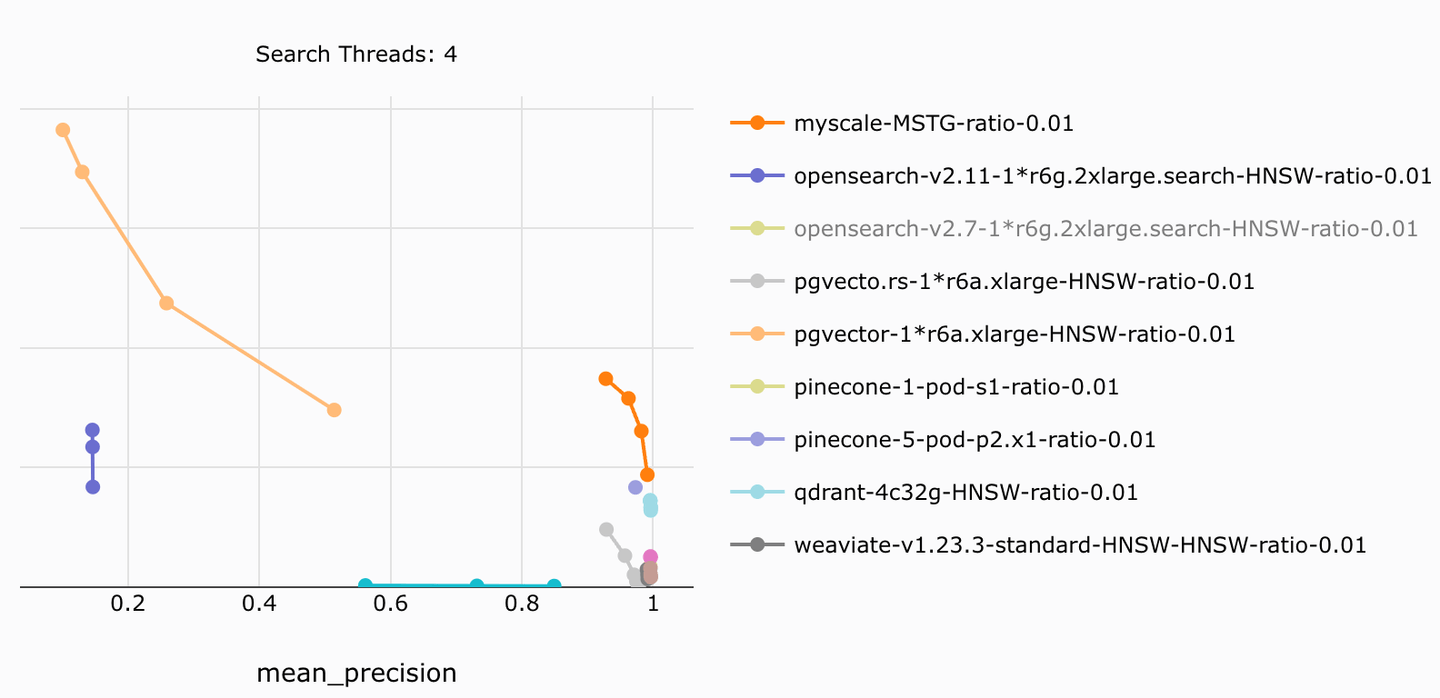
过滤向量搜索在大规模数据检索中至关重要,显著提高检索精度。MyScale通过预过滤和列存储等技术,实现高效的过滤搜索,支持多用户系统。在金融分析等应用中,精度可从60%提升至90%。结合结构化数据与向量数据,MyScale为大规模LLM应用奠定了基础。
🎯
关键要点
-
过滤向量搜索在大规模数据检索中至关重要,显著提高检索精度。
-
MyScale通过预过滤和列存储等技术,实现高效的过滤搜索,支持多用户系统。
-
在金融分析等应用中,精度可从60%提升至90%。
-
结合结构化数据与向量数据,MyScale为大规模LLM应用奠定了基础。
-
预过滤和后过滤是实现元数据过滤的两种方法,预过滤能保证结果的准确性。
-
列存储在分析处理上效率更高,适合大规模数据的扫描和分析。
-
MyScale通过结合高效的预过滤和算法创新,确保在任何过滤比例下都能保持高精度和效率。
❓
延伸问答
过滤向量搜索的主要优势是什么?
过滤向量搜索显著提高了检索精度,尤其是在处理大规模数据时,可以将精度从60%提升至90%。
MyScale是如何实现高效的过滤搜索的?
MyScale通过结合预过滤、列存储和高效的搜索算法,实现了高效的过滤搜索,支持多用户系统。
预过滤和后过滤有什么区别?
预过滤先选择符合条件的向量再进行搜索,确保结果的准确性;而后过滤则是在获得初步结果后再应用过滤条件,可能导致最终结果不确定。
列存储在数据分析中有什么优势?
列存储在分析处理上效率更高,适合大规模数据的扫描和分析,能够显著提高数据检索性能。
过滤向量搜索在金融分析中的应用效果如何?
在金融分析中,过滤向量搜索可以将检索精度从60%提升至90%,有效提高信息检索的准确性。
MyScale与其他向量数据库相比有什么优势?
MyScale在搜索速度和精度上表现优异,且成本比其他产品低4到10倍,适合生产级RAG系统。
🏷️
