
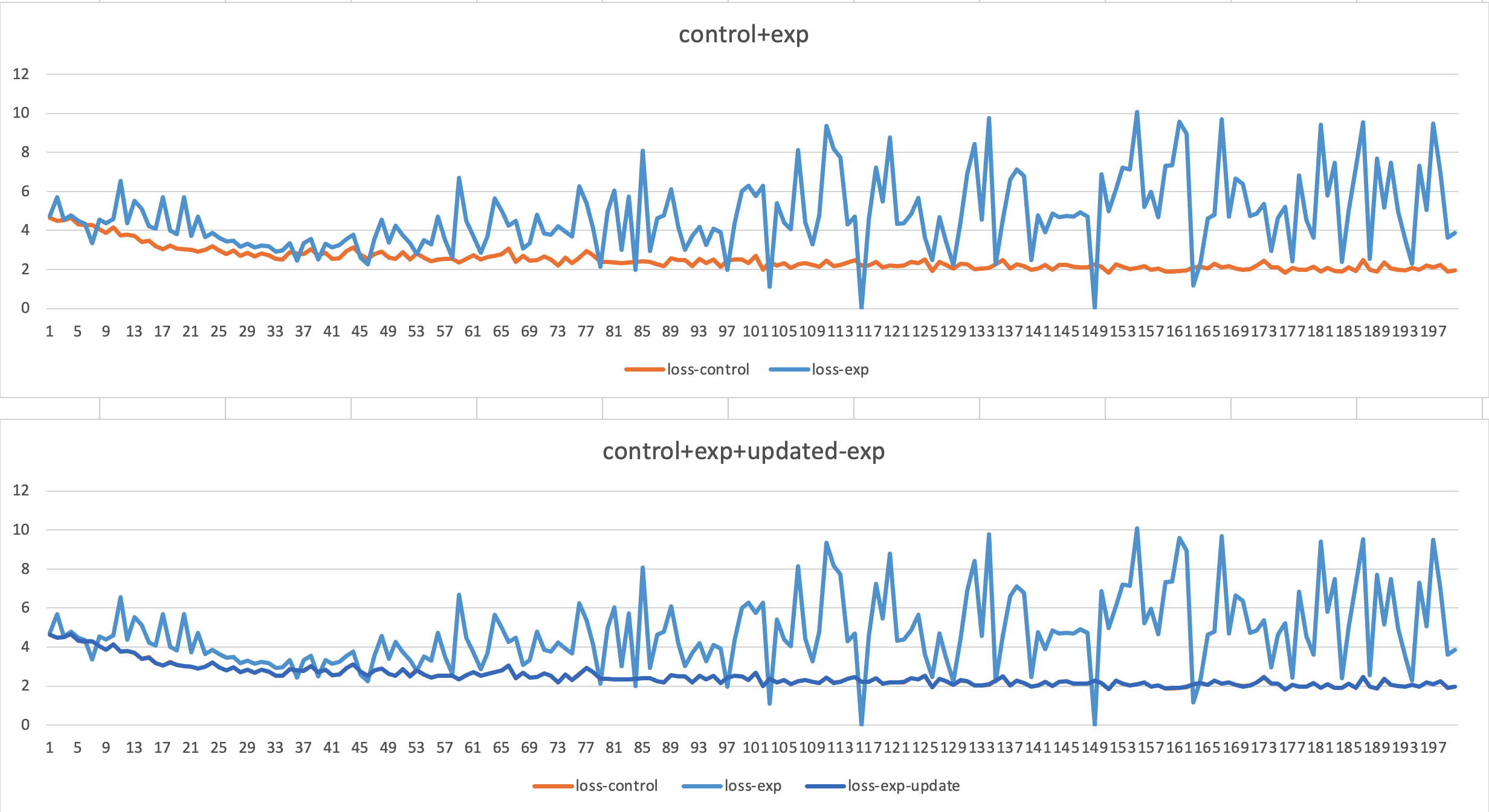
经过验证的大语言模型加速示例
内容提要
本文探讨了快速交叉熵损失在大语言模型加速中的应用,通过优化计算过程,时间复杂度从O(4n)降低到O(2n),显著减少了训练时间和GPU内存。以Gemma2为例,新方法在微调时减少了4.8%的时间成本,验证了与默认PyTorch代码结果的一致性,整体提高了效率,展示了LLM加速的潜力。
关键要点
-
快速交叉熵损失在大语言模型加速中的应用,通过优化计算过程,时间复杂度从O(4n)降低到O(2n)。
-
以Gemma2为例,新方法在微调时减少了4.8%的时间成本,验证了与默认PyTorch代码结果的一致性。
-
新方法通过减去最大logit来提高softmax的稳定性,确保了新代码与默认代码的损失几乎没有差异。
-
在微调Gemma2的实验中,新代码的平均时间为352.5秒,较官方代码减少了2.8%的时间成本。
-
使用Triton实现可能会有更好的性能,表明还有更多类似的方法可以加速LLM的训练过程。
延伸解读
快速交叉熵损失的优势
快速交叉熵损失通过优化计算过程,显著降低了时间复杂度,从O(4n)降至O(2n)。这种优化不仅减少了训练时间,还降低了GPU内存的使用,适合大语言模型的训练需求。对于需要高效计算的深度学习任务,这种方法提供了新的思路和解决方案。
微调效果的验证
在微调Gemma2的实验中,新方法减少了4.8%的时间成本,且与默认PyTorch代码的结果一致。这表明新方法在实际应用中具有可行性,能够在保持模型性能的同时提高训练效率。研究者在选择优化方法时,应关注其对训练时间和资源消耗的影响。
未来的加速潜力
文章提到使用Triton实现可能会带来更好的性能,这暗示了在大语言模型训练中还有更多优化空间。研究者应关注新技术的应用,以进一步提升模型训练的效率和效果,推动深度学习领域的发展。
延伸问答
快速交叉熵损失如何加速大语言模型的训练?
快速交叉熵损失通过优化计算过程,将时间复杂度从O(4n)降低到O(2n),显著减少了训练时间和GPU内存。
Gemma2微调中使用新方法的效果如何?
在微调Gemma2时,新方法减少了4.8%的时间成本,且与默认PyTorch代码结果一致。
新方法如何确保与默认代码的损失一致性?
新方法通过减去最大logit来提高softmax的稳定性,确保新代码与默认代码的损失几乎没有差异。
使用Triton实现有什么潜在优势?
使用Triton实现可能会有更好的性能,表明还有更多类似的方法可以加速LLM的训练过程。
新方法在时间成本上与官方代码相比有何变化?
新代码的平均时间为352.5秒,较官方代码减少了2.8%的时间成本。
快速交叉熵损失的理论基础是什么?
快速交叉熵损失的理论基础是针对大语言模型训练中目标值的特殊性,优化了交叉熵损失的计算过程。
