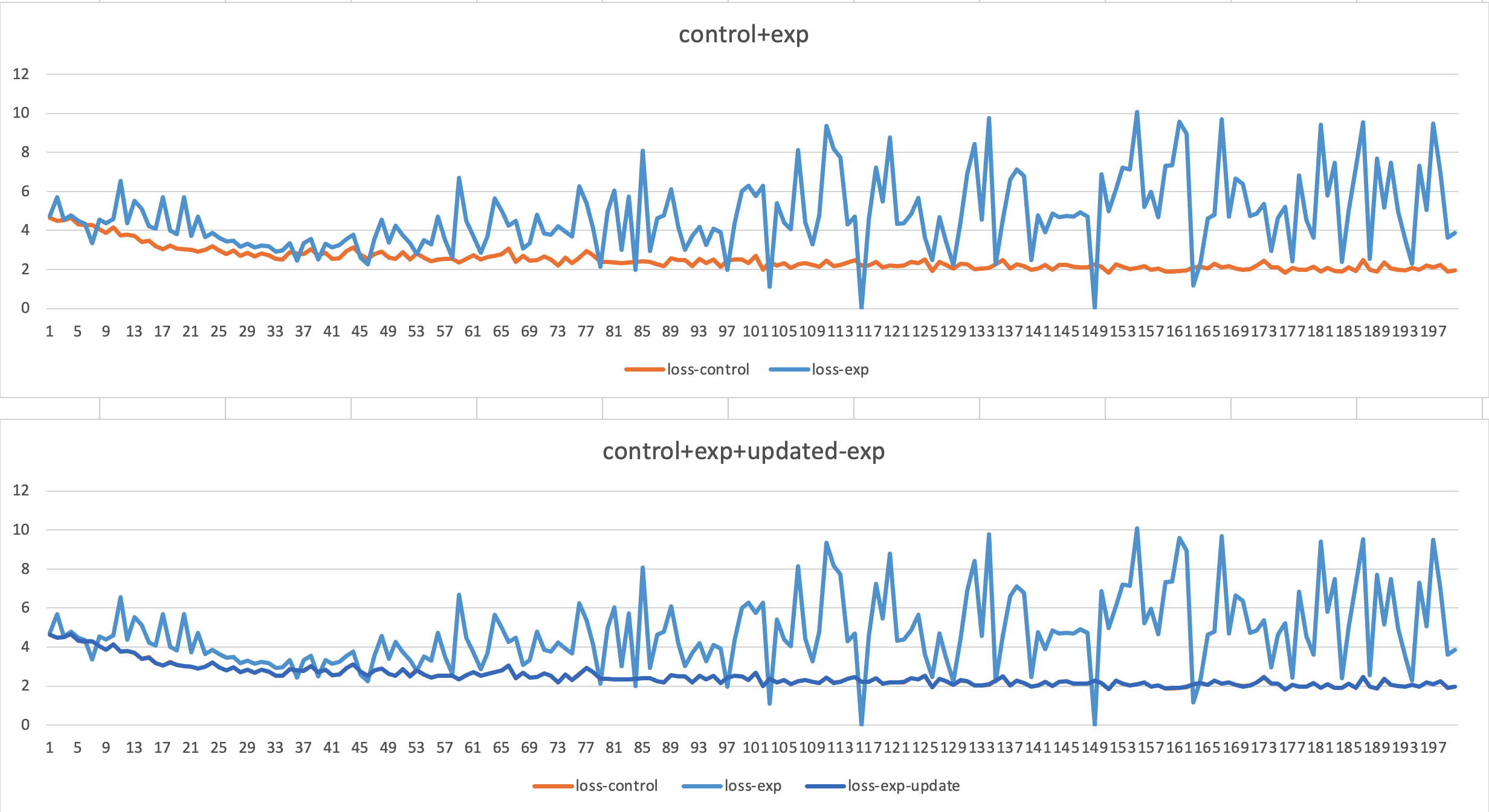
本文探讨了快速交叉熵损失在大语言模型加速中的应用,通过优化计算过程,时间复杂度从O(4n)降低到O(2n),显著减少了训练时间和GPU内存。以Gemma2为例,新方法在微调时减少了4.8%的时间成本,验证了与默认PyTorch代码结果的一致性,整体提高了效率,展示了LLM加速的潜力。
完成下面两步后,将自动完成登录并继续当前操作。