
使用Databricks Agent Bricks构建合规风险助手(第一部分:信息提取)
内容提要
Databricks提供统一平台,促进业务专家与AI工程师实时协作,构建高质量AI系统。通过四个步骤,从解析PDF到提取关键信息,确保快速迭代与准确性,提升数据处理效率,帮助企业获得竞争优势。
关键要点
-
Databricks提供统一平台,促进业务专家与AI工程师实时协作,构建高质量AI系统。
-
通过建立基线,Databricks工具提供评估功能,强调质量,确保快速迭代与准确性。
-
工程师常常在孤立环境中开发,导致AI构建与业务需求之间存在差距。
-
Databricks帮助加速从PDF中提取关键信息,将这些信息转化为可操作的智能。
-
有效利用非结构化数据的能力成为企业竞争优势,尤其是在FDA发布的新CRL中。
-
构建生产质量AI系统需要无缝、迭代和协作的工作流程。
-
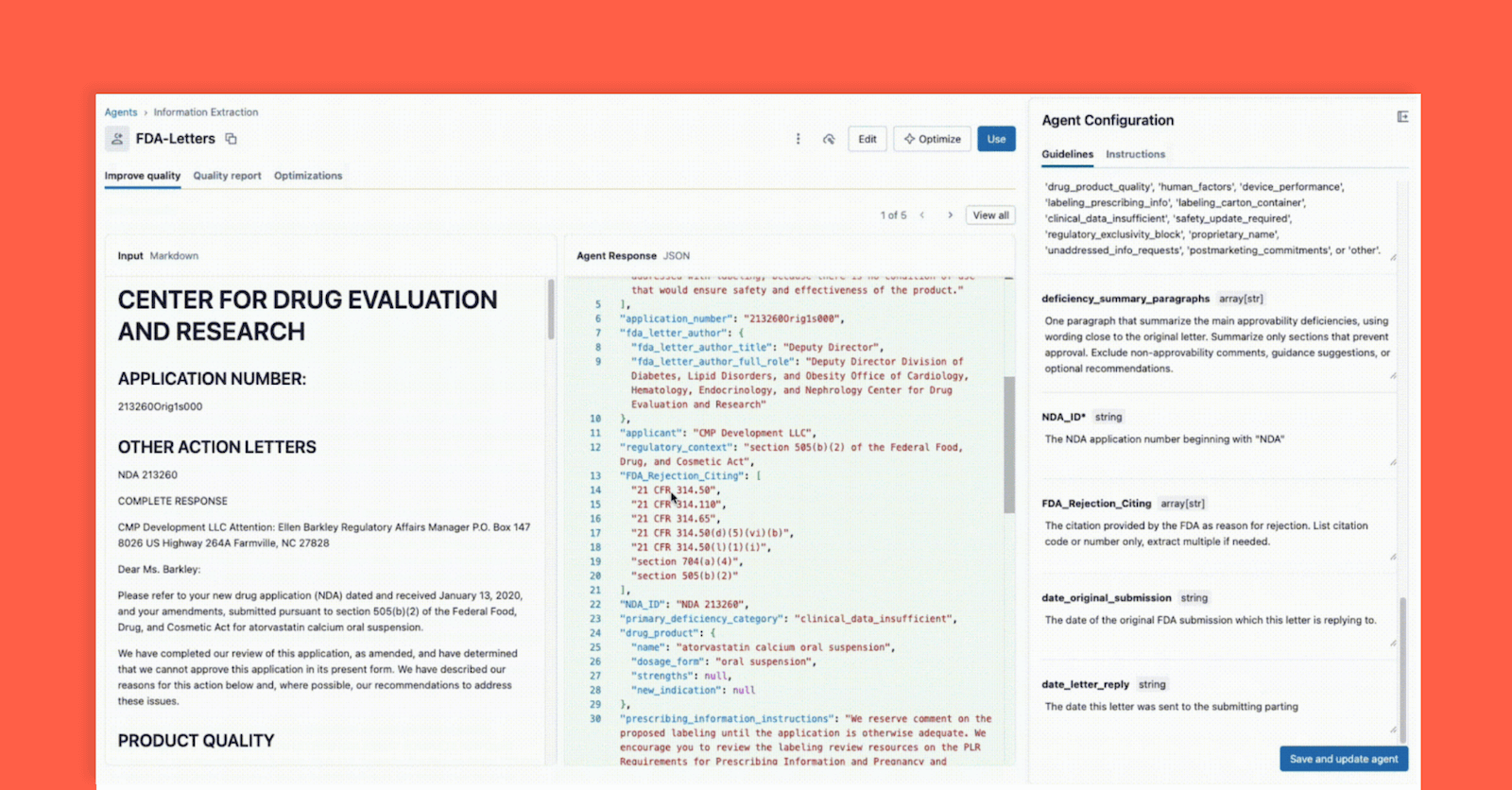
第一步是使用ai_parse_document()将非结构化PDF解析为文本。
-
第二步是通过Agent Bricks进行迭代信息提取,促进技术领导与业务专家的紧密合作。
-
第三步是评估和验证代理,确保高准确性和可扩展性。
-
第四步是将代理与ai_query()集成到ETL管道中,实现自动化的生产级ETL流程。
-
Databricks打破技术团队与领域专家之间的壁垒,促进紧密的迭代合作。
-
Agent Bricks结合ai_parse_document()、信息提取的协作设计界面和ai_query(),加速从PDF到验证洞察的过程。
延伸解读
协作的重要性
在构建AI系统时,技术团队与业务专家之间的紧密合作至关重要。Databricks通过Agent Bricks提供实时协作界面,使得双方能够快速反馈和调整提取信息的策略,从而提高提取的准确性和效率。这种协作不仅能缩短开发周期,还能确保最终产品更符合业务需求。
处理非结构化数据的挑战
随着FDA发布新CRL,企业需要快速从非结构化数据中提取有价值的信息。然而,PDF格式的数据处理复杂,传统方法往往无法高效提取关键信息。Databricks的ai_parse_document()功能通过先进的多模态AI技术,能够准确解析复杂布局的PDF,帮助企业在竞争中获得优势。
评估与验证的必要性
在信息提取过程中,确保高准确性和可扩展性是成功的关键。Databricks的Agent Bricks提供了两种评估方法:使用标注数据进行验证和利用LLM作为评估者。这些方法能够帮助团队及时发现问题并进行调整,确保提取结果的可靠性,降低项目风险。
延伸问答
Databricks如何促进业务专家与AI工程师的协作?
Databricks提供统一平台,允许业务专家与AI工程师实时合作,构建高质量的AI系统。
使用Databricks进行信息提取的四个步骤是什么?
四个步骤包括:解析PDF为文本、通过Agent Bricks进行信息提取、评估和验证代理、将代理与ai_query()集成到ETL管道中。
如何确保信息提取的准确性和可扩展性?
通过使用Ground Truth标签进行评估,或利用LLM作为评估者来验证提取的准确性。
Databricks在处理复杂PDF时有什么优势?
Databricks使用ai_parse_document(),能够准确提取文本,处理复杂布局,并以更低的成本处理企业级文档。
Agent Bricks的作用是什么?
Agent Bricks提供实时协作界面,帮助技术领导与业务专家共同提取特定的结构化信息。
如何将提取的代理集成到ETL管道中?
使用ai_query()函数,可以将提取逻辑作为无服务器模型端点集成到ETL管道中,实现自动化处理。
