
BGE M3-Embedding 模型介绍 - JadePeng
内容提要
BGE M3-Embedding是由BAAI和中国科学技术大学开发的开源模型,支持100多种语言,最大输入长度为8192。该模型结合稠密、稀疏和多向量检索技术,显著提升信息检索效果,尤其在多语言和长文档检索中表现优异,特别是在跨语言任务中。
关键要点
-
BGE M3-Embedding是由BAAI和中国科学技术大学开发的开源模型,支持超过100种语言。
-
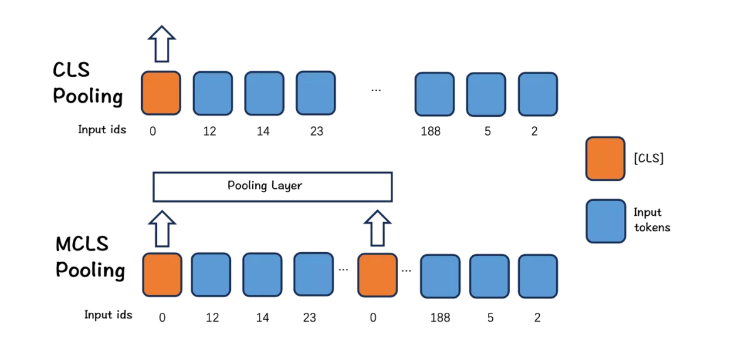
该模型的最大输入长度为8192,支持稠密检索、稀疏检索和多向量检索。
-
BGE-M3在多语言和跨语言检索中表现优异,尤其在长文档检索中效果显著。
-
模型训练分为三个阶段:RetroMAE预训练、无监督对比学习和多检索方式统一优化。
-
BGE-M3采用自学习蒸馏方法提高检索性能,并通过训练效率优化和长文本优化增强模型能力。
-
在多语言检索任务中,稀疏检索的效果超过传统算法BM25,跨语言检索能力表现最佳。
延伸解读
多语言支持的优势
BGE M3-Embedding模型支持超过100种语言,这使其在全球范围内的信息检索应用中具有广泛的适用性。尤其在多语言环境中,用户可以更方便地进行跨语言检索,提升了信息获取的效率和准确性。
长文档检索的能力
该模型能够处理最大8192个词符的长文档,特别适合需要深入分析的文本。实验表明,稀疏检索在长文档检索中表现优异,强调了关键词信息的重要性,用户在使用时应关注关键词的选择与优化。
检索方式的多样性
BGE M3-Embedding结合了稠密、稀疏和多向量检索技术,提供了灵活的检索方式。用户可以根据具体需求选择合适的检索方式,以实现最佳的检索效果,尤其是在处理复杂查询时。
延伸问答
BGE M3-Embedding模型的主要特点是什么?
BGE M3-Embedding模型支持超过100种语言,最大输入长度为8192,结合稠密、稀疏和多向量检索技术,提升信息检索效果。
BGE M3-Embedding模型如何进行训练?
模型训练分为三个阶段:RetroMAE预训练、无监督对比学习和多检索方式统一优化。
BGE M3-Embedding在多语言检索中表现如何?
在多语言检索任务中,BGE M3-Embedding的稀疏检索效果超过传统算法BM25,表现优异。
BGE M3-Embedding模型的输入限制是什么?
该模型支持最大长度为8192的输入文本,可以处理句子、段落、篇章和文档等不同粒度的输入。
BGE M3-Embedding模型的自学习蒸馏方法有什么作用?
自学习蒸馏方法通过合并多种检索模式的输出,提升单检索模式的效果。
BGE M3-Embedding模型在长文档检索中的表现如何?
在长文档检索中,BGE M3-Embedding的稀疏检索效果显著高于稠密检索,关键词信息对长文档检索至关重要。
