
ICLR 2026丨英伟达/牛津大学等提出原子级蛋白质结合剂生成方法,性能达SOTA级别
内容提要
在计算生物学中,设计精准结合的蛋白质是一个关键挑战。机器学习的引入改变了这一领域,Complexa框架通过结合生成与优化,提高了结合剂设计的效率和成功率,推动了人工智能在蛋白质设计中的应用。
关键要点
-
计算生物学中设计精准结合的蛋白质是核心挑战,影响药物研发和生物制造效率。
-
蛋白质与靶点的结合是三维结构问题,结合剂设计方法需依赖结构解析或预测。
-
机器学习的引入改变了蛋白质设计的范式,推动从解析结构到生成结构的转变。
-
当前AI驱动的结合剂设计方法分为生成式和幻觉式,存在生成与优化的分离。
-
Complexa框架旨在弥合生成式与幻觉式方法之间的断层,实现生成与优化的统一。
-
Complexa基于Teddymer预训练,能够高效进行从头结合剂设计,无需额外序列重新设计。
-
研究提出的人工多聚体构建方法将单体结构重新解释为复合体数据来源,扩展了数据规模。
-
Complexa模型通过条件生成机制,专注于生成结合剂部分,提升了生成质量和效率。
-
模型在推理阶段引入计算扩展机制,能够动态提升生成质量,增强可扩展性。
-
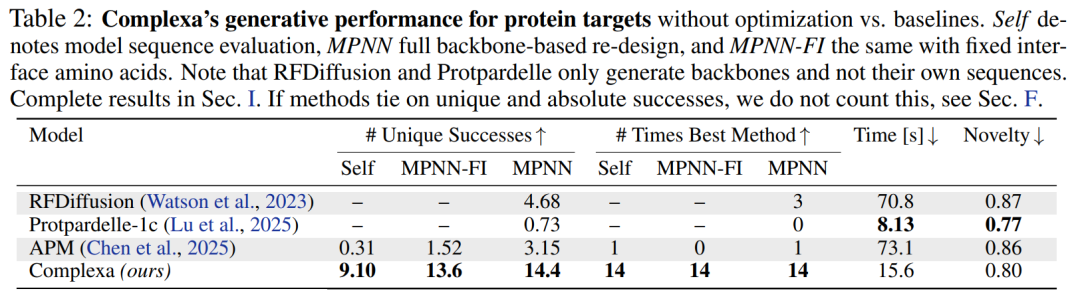
Complexa在基础生成能力、结构可控性和物理合理性方面均优于现有方法。
-
AI蛋白质设计正加速从理论走向实践,产业界关注其工程化落地,推动研发流程的闭环迭代。
-
蛋白质设计的竞争正从单一模型性能转向系统级效率与可扩展性,进入更实际的阶段。
延伸解读
蛋白质设计的挑战与机遇
蛋白质结合剂的设计是计算生物学中的核心挑战,直接影响药物研发和生物制造的效率。随着机器学习的引入,设计方法逐渐从依赖实验结构转向生成结构,这为从头设计提供了新的可能性,显著降低了研发成本和周期。
Complexa框架的创新
Complexa框架通过将生成与优化机制结合,弥补了当前AI结合剂设计方法的不足。其基于Teddymer的预训练,能够高效进行从头设计,且无需额外的序列重新设计,提升了生成质量和效率,标志着蛋白质设计的一个重要进步。
数据限制与解决方案
蛋白质结合剂生成模型的一个主要限制在于数据的稀缺性。研究通过重新解释单体结构为潜在的复合体数据来源,提出了人工多聚体构建方法,扩展了数据规模。这一创新为模型的规模化训练提供了新的思路。
AI蛋白质设计的未来趋势
AI驱动的蛋白质设计正加速从理论走向实践,产业界对其工程化落地的关注日益增加。未来的竞争将不仅限于模型性能,而是系统级的效率与可扩展性,推动研发流程的闭环迭代,标志着AI在生物工程领域的深远影响。
延伸问答
Complexa框架的主要目标是什么?
Complexa框架旨在弥合生成式与幻觉式方法之间的断层,实现生成与优化的统一。
机器学习如何改变蛋白质结合剂的设计?
机器学习的引入使得蛋白质结合剂设计从依赖实验结构转向生成结构,显著压缩研发成本与周期。
Complexa模型在生成能力上有哪些优势?
Complexa模型在基础生成能力、结构可控性和物理合理性方面均优于现有方法,能够生成高质量的结合剂。
如何解决蛋白质结合剂生成模型的数据限制?
研究提出了一种人工多聚体构建方法,将单体结构重新解释为复合体数据来源,从而扩展数据规模。
Complexa框架如何提高生成剂的质量?
Complexa通过条件生成机制专注于生成结合剂部分,并在推理阶段引入计算扩展机制,动态提升生成质量。
AI蛋白质设计的未来趋势是什么?
AI蛋白质设计正加速从理论走向实践,产业界关注其工程化落地,推动研发流程的闭环迭代。
