
用本地Qwen3大模型驱动中文输入法,我做了一个实验性的项目
内容提要
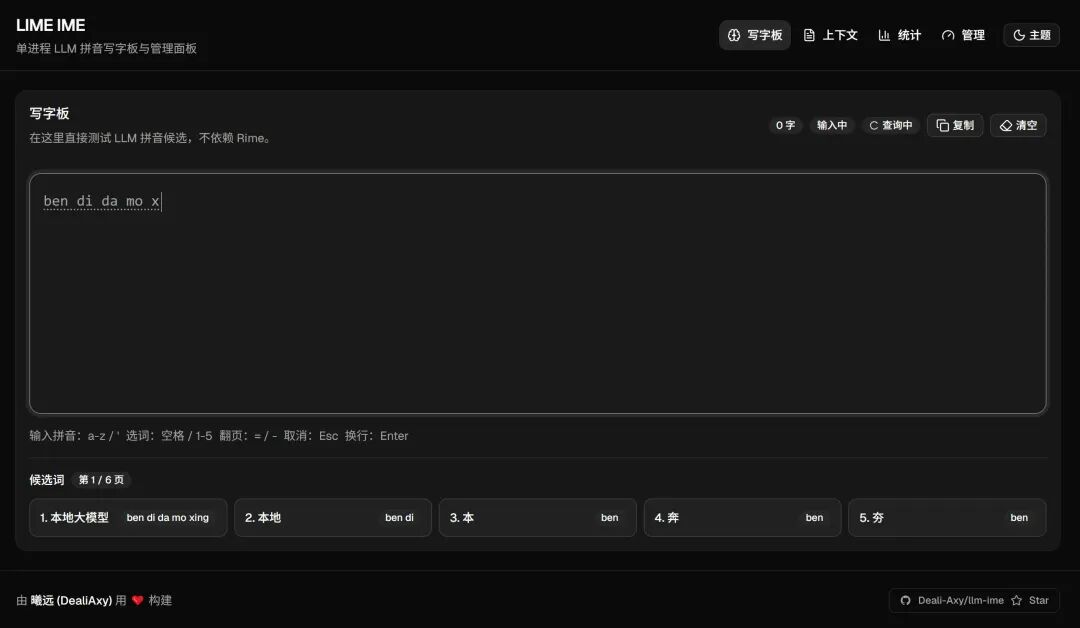
该项目llm-ime旨在利用大语言模型(LLM)改善拼音输入法的候选词排序。与传统基于词频的输入法不同,LLM能够通过分析上下文提供更符合语境的候选词。项目目前使用本地量化模型以确保隐私,现处于Web验证阶段,未来计划接入真实输入法框架并优化候选词评分策略。
关键要点
-
传统拼音输入法的候选词排序基于词频统计,无法理解上下文。
-
大语言模型(LLM)能够通过分析上下文提供更符合语境的候选词。
-
llm-ime项目旨在利用LLM改善拼音输入法的候选词排序。
-
项目使用本地量化模型,确保用户隐私,当前处于Web验证阶段。
-
未来计划接入真实输入法框架并优化候选词评分策略。
-
项目核心是一个Node.js服务,加载本地GGUF格式的量化模型,返回按语境排序的候选词。
-
模型Qwen3-0.6B-IQ4_XS具有小巧、快速和准确的特点,完全在本地运行,保障隐私。
-
项目架构包括LLM推理引擎、React前端和共享组件库,设计上注重响应速度和用户体验。
-
当前效果仍需优化,候选词排序和长句联想的稳定性有待提高。
延伸解读
大语言模型的优势
传统拼音输入法依赖词频统计,无法理解上下文,导致候选词排序不准确。而大语言模型(LLM)通过分析上下文,能够提供更符合语境的候选词。这种能力使得用户在输入时能更快找到所需词汇,提高输入效率。
隐私保护的重要性
llm-ime项目使用本地量化模型,确保用户隐私不被泄露。与许多在线输入法不同,该项目完全在本地运行,避免了数据上传的风险。这对于关注隐私的用户来说,是一个重要的优势。
项目的未来发展方向
目前llm-ime项目仍处于Web验证阶段,候选词排序和长句联想的稳定性有待提高。未来计划接入真实输入法框架并优化评分策略,用户可以期待更好的使用体验和更高的准确性。
延伸问答
llm-ime项目的主要目标是什么?
llm-ime项目旨在利用大语言模型改善拼音输入法的候选词排序,提供更符合语境的候选词。
与传统拼音输入法相比,llm-ime有什么优势?
llm-ime通过分析上下文提供候选词排序,而传统输入法仅基于词频统计,无法理解上下文。
llm-ime项目目前处于哪个阶段?
项目目前处于Web验证阶段,正在测试引擎逻辑和响应速度。
llm-ime使用了什么样的模型?
llm-ime使用的是Qwen3-0.6B-IQ4_XS模型,具有小巧、快速和准确的特点,完全在本地运行。
如何在本地运行llm-ime项目?
可以通过克隆项目、下载模型并启动服务来在本地运行llm-ime项目。
llm-ime项目未来的计划是什么?
未来计划接入真实输入法框架并优化候选词评分策略,改善长句联想的稳定性。
