
微小故事,大差异:小型模型如何学习区域语言
原文英文,约200词,阅读约需1分钟。
📝
内容提要
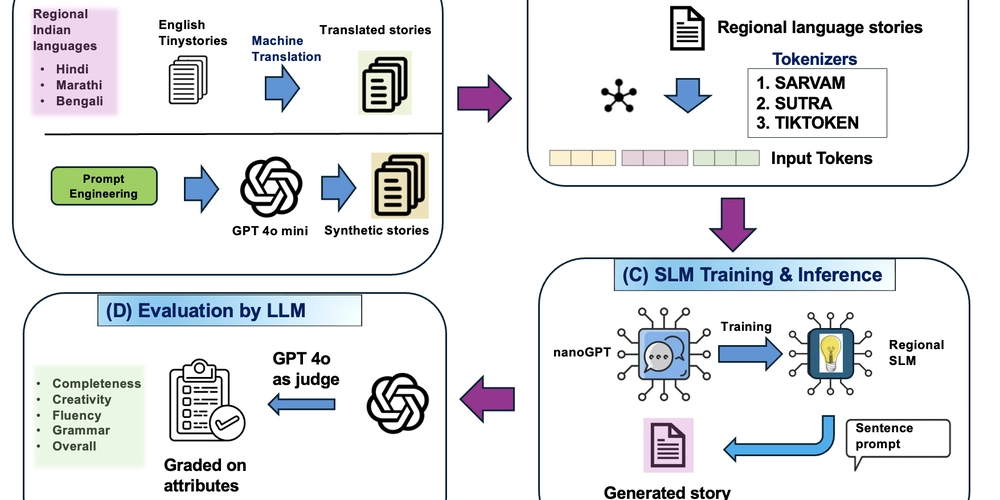
研究论文《微小故事,大差异》探讨小型语言模型如何学习不同地区的语言。研究团队通过短故事测试AI模型对多种语言的理解能力。
🎯
关键要点
-
研究论文《微小故事,大差异》探讨小型语言模型如何学习不同地区的语言。
-
研究团队通过短故事测试AI模型对多种语言的理解能力。
-
研究比较了使用小型数据集的语言模型性能。
-
测试了小型数据集上区域语言学习能力。
-
评估了不同语言的多种分词器方法。
-
使用控制实验,每种语言有2500个故事。
-
研究了分词器和模型大小如何影响语言理解。
🔎
延伸解读
小型模型的优势与局限
小型语言模型在处理特定区域语言时展现出独特的优势,尤其是在数据量有限的情况下。然而,它们的性能可能受到模型大小和分词器选择的影响,因此在实际应用中需要谨慎评估其适用性。
区域语言学习的实践意义
研究表明,通过短故事的方式测试小型模型的语言理解能力,可以有效评估其在特定文化和语言背景下的表现。这为多语言应用开发提供了新的思路,尤其是在资源稀缺的语言环境中。
分词器选择的重要性
不同的分词器对语言模型的理解能力有显著影响。研究强调了在构建多语言模型时,选择合适的分词器是提升模型性能的关键因素之一,开发者应对此给予足够重视。
❓
延伸问答
小型语言模型如何学习不同地区的语言?
小型语言模型通过分析短故事来学习不同地区的语言和写作风格。
研究中使用了多少个故事来测试每种语言?
研究中每种语言使用了2500个故事进行测试。
研究比较了哪些方面的语言模型性能?
研究比较了使用小型数据集的语言模型性能以及不同分词器方法的效果。
分词器和模型大小对语言理解有什么影响?
研究探讨了分词器和模型大小如何影响小型语言模型的语言理解能力。
这项研究的主要目的是什么?
这项研究的主要目的是探讨小型语言模型如何学习和理解不同地区的语言。
研究团队如何评估AI模型的语言理解能力?
研究团队通过控制实验和短故事测试AI模型的语言理解能力。
🏷️
