

在Databricks上构建高并发、低延迟的数据仓库以实现可扩展性
💡
原文英文,约4600词,阅读约需17分钟。
📝
内容提要
在Databricks数据仓库中,实现高并发和低延迟的生产级分析至关重要。湖仓架构整合数据、分析和AI工作负载,简化操作并降低成本。通过优化性能和治理框架,企业能够快速做出实时决策,提高数据仓库的效率和可扩展性。
🎯
关键要点
- 在Databricks数据仓库中,实现高并发和低延迟的生产级分析至关重要。
- 湖仓架构整合数据、分析和AI工作负载,简化操作并降低成本。
- 通过优化性能和治理框架,企业能够快速做出实时决策,提高数据仓库的效率和可扩展性。
- 核心架构组件对平台性能的影响需要全面考虑,包括统一治理框架和Unity Catalog。
- 有效设计需要采用经过验证的架构最佳实践,理解互联组件之间的权衡。
- 现代湖仓架构与传统数据仓库在计算和存储、工作负载支持、计算弹性、优化和治理等方面存在显著差异。
- 实施框架包括用例驱动评估、定义仓库架构和治理、启用可观察性、实施优化和最佳实践。
- 在实施前,快速评估关键工作负载以识别性能差距并优先优化。
- 计算资源的合理配置和数据布局设计直接影响性能,需进行细致的规划和调整。
- 物理数据布局优化对于高并发、低延迟性能至关重要,需选择合适的数据组织策略。
- 数据建模应基于业务需求,使用Unity Catalog提供的功能来优化查询性能。
- 持续监控和调整是确保高性能和成本效率的关键,需建立可观察性和自动化警报机制。
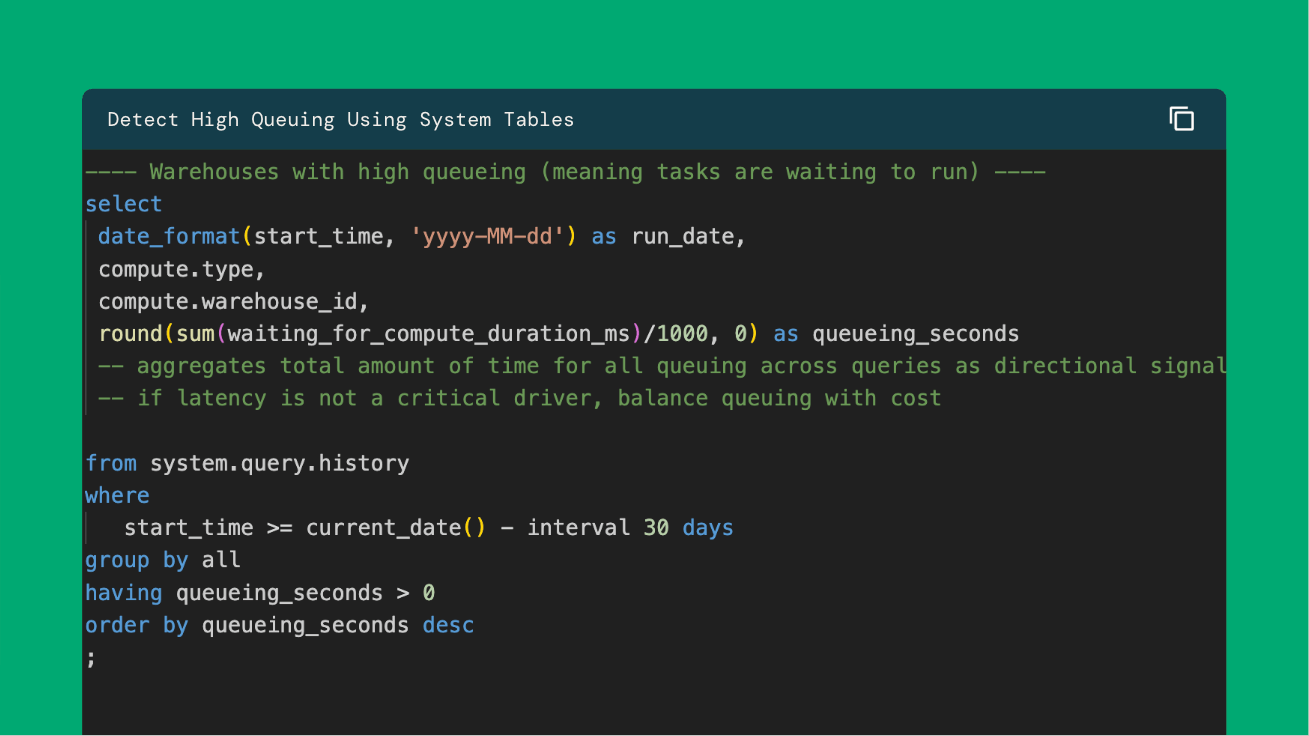
- 性能问题通常归结为存储、小文件、数据倾斜、溢出和排队等因素,需针对性解决。
- 通过系统化的方法,持续监控、优化并确保新工作负载遵循优化蓝图,以满足并发、延迟和可扩展性要求。
➡️
