
OpenMOSS发布MOSS-Audio:一个用于语音、声音、音乐和时间感知音频推理的开源基础模型
内容提要
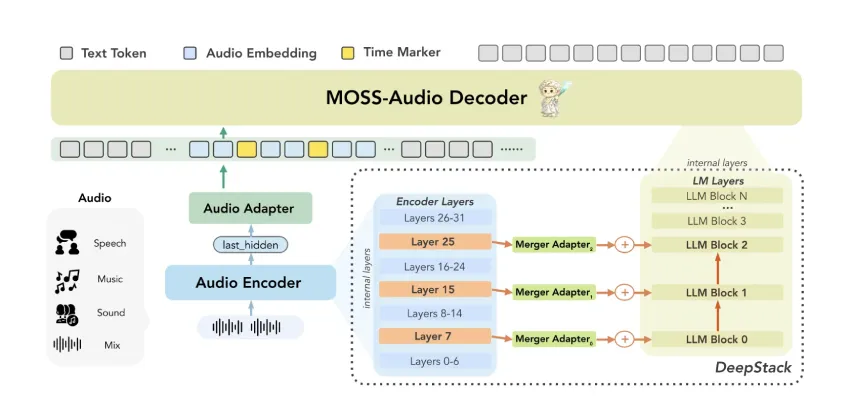
MOSS-Audio是一个开源音频理解模型,集成了语音转录、情感分析和环境声音理解等功能。其模块化设计包括音频编码器和大型语言模型,采用DeepStack跨层特征注入和时间感知表示技术,显著提升了音频处理能力。MOSS-Audio-8B-Thinking在音频理解基准测试中表现优异,准确率达到71.08%。
关键要点
-
MOSS-Audio是一个开源音频理解模型,集成了语音转录、情感分析和环境声音理解等功能。
-
MOSS-Audio支持语音理解、环境音理解、音乐理解、音频字幕、时间感知问答和复杂推理。
-
该模型采用模块化设计,包含音频编码器、模态适配器和大型语言模型。
-
MOSS-Audio通过DeepStack跨层特征注入和时间感知表示技术提升音频处理能力。
-
MOSS-Audio-8B-Thinking在音频理解基准测试中表现优异,准确率达到71.08%。
-
该模型的四个变体分别针对不同的任务需求,提供了多种选择。
-
MOSS-Audio在语音字幕和自动语音识别方面的表现优于大多数开源模型。
延伸解读
MOSS-Audio的多功能性
MOSS-Audio不仅支持语音转录,还能进行情感分析和环境声音理解。这种多功能性使其在处理复杂音频任务时具备显著优势,尤其适用于需要综合分析的场景,如会议记录和播客内容的处理。
架构创新的意义
MOSS-Audio采用的DeepStack跨层特征注入和时间感知表示技术,显著提升了音频处理的准确性和效率。这些创新使得模型能够更好地捕捉音频中的细节信息,适应多种应用场景,尤其是在需要时间敏感的任务中表现突出。
模型选择的考量
MOSS-Audio提供了四种变体,用户在选择时应考虑任务需求。'指令'变体适合结构化输出,而'思考'变体则更适合复杂推理任务。了解这些差异可以帮助用户更有效地利用模型,提升工作效率。
延伸问答
MOSS-Audio的主要功能是什么?
MOSS-Audio支持语音理解、环境音理解、音乐理解、音频字幕、时间感知问答和复杂推理等功能。
MOSS-Audio的架构是怎样的?
MOSS-Audio采用模块化设计,包含音频编码器、模态适配器和大型语言模型。
MOSS-Audio的DeepStack技术有什么优势?
DeepStack技术通过跨层特征注入保留多粒度声学信息,解决了音频模型常见的特征丢失问题。
MOSS-Audio在基准测试中的表现如何?
MOSS-Audio-8B-Thinking在音频理解基准测试中平均准确率达到71.08%,优于大多数开源模型。
MOSS-Audio有哪些不同的变体?
MOSS-Audio有四个变体:MOSS-Audio-4B-Instruct、MOSS-Audio-4B-Thinking、MOSS-Audio-8B-Instruct和MOSS-Audio-8B-Thinking。
MOSS-Audio如何处理时间感知任务?
MOSS-Audio通过在预训练期间插入时间标记,使模型能够学习事件发生的时间,支持时间戳自动语音识别等任务。
