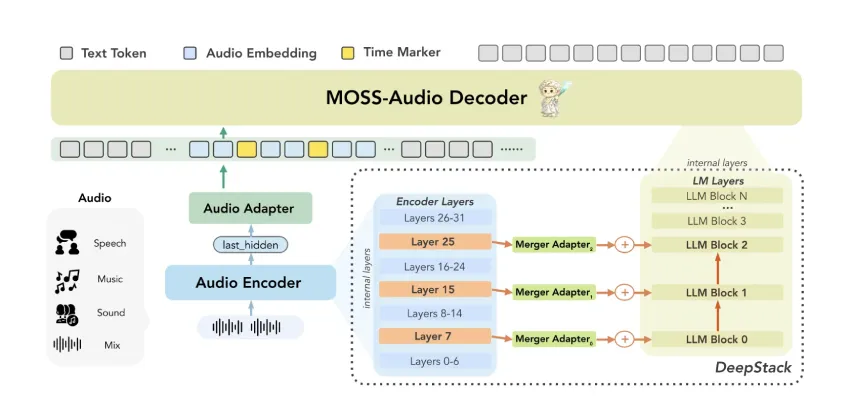
MOSS-Audio是一个开源音频理解模型,集成了语音转录、情感分析和环境声音理解等功能。其模块化设计包括音频编码器和大型语言模型,采用DeepStack跨层特征注入和时间感知表示技术,显著提升了音频处理能力。MOSS-Audio-8B-Thinking在音频理解基准测试中表现优异,准确率达到71.08%。
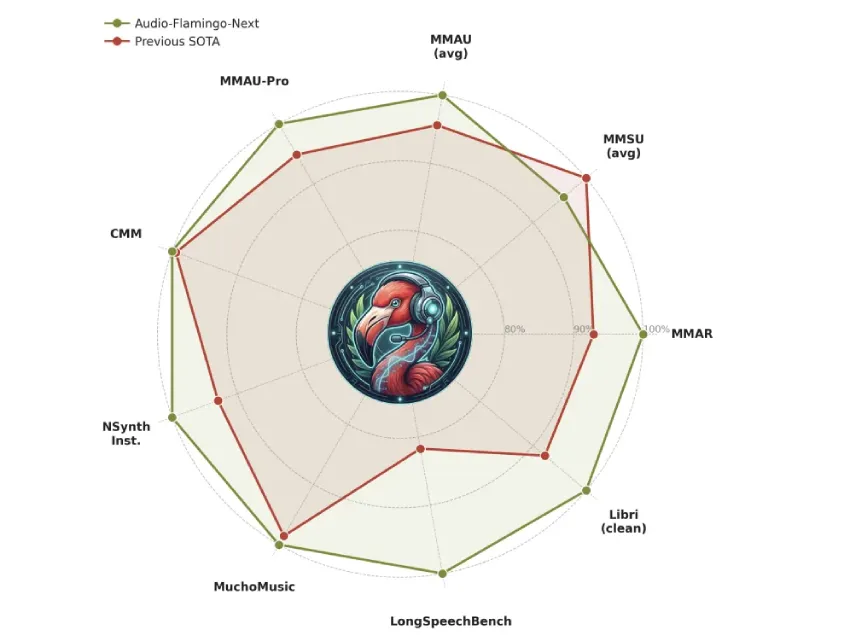
NVIDIA与马里兰大学推出了Audio Flamingo Next(AF-Next),这是一个开放的大型音频语言模型,旨在提升音频理解能力。AF-Next有三种版本,分别用于问答、多步骤推理和音频字幕生成。该模型通过时间音频思维链技术,能够更准确地处理长达30分钟的录音,并在长音频理解和音乐识别方面表现优异。
AES发布技术文件TD1009,旨在提升媒体对话清晰度,解决观众音频理解问题。研究分析了对话从采集到呈现的全过程,提出改善后期制作、设备限制及发行环节的方案,鼓励行业人士应用以提升听众体验。
本研究提出了音频为中心的视频理解基准(ACVUBench),旨在评估多模态大型语言模型对音频信息的理解能力。基准包含2,662段视频和超过13,000个问答对,设计了音频中心任务,以展示音频-视觉模型的不足。
Ola模型是一种全模态语言模型,具备图像、视频和音频理解的强大能力。其采用渐进式模态对齐策略,逐步提升模型性能。在多个基准测试中,Ola超越了现有的专用模型,推动了全模态理解的研究进展。
本文探讨了多种先进语音编码器在低资源环境下的表现,特别是Whisper在语音理解和生成任务中的优越性。研究还介绍了Speech-LLaMA和Qwen-Audio模型,后者通过多任务训练框架提升了音频理解能力,并支持多轮对话。研究提出了新的训练策略和评估基准,以解决语音识别和翻译模型的数据不足问题。
本研究探讨了音频问题回答(AQA)任务中的时间推理能力,提出了多种模型以提升性能,包括MALiMo和INDENT。研究表明,利用多模态知识和新数据集可以显著改善音频场景理解和问题定位能力。此外,GAMA模型在音频理解任务中表现优异,解决了文本到音频检索中的时间顺序理解问题。
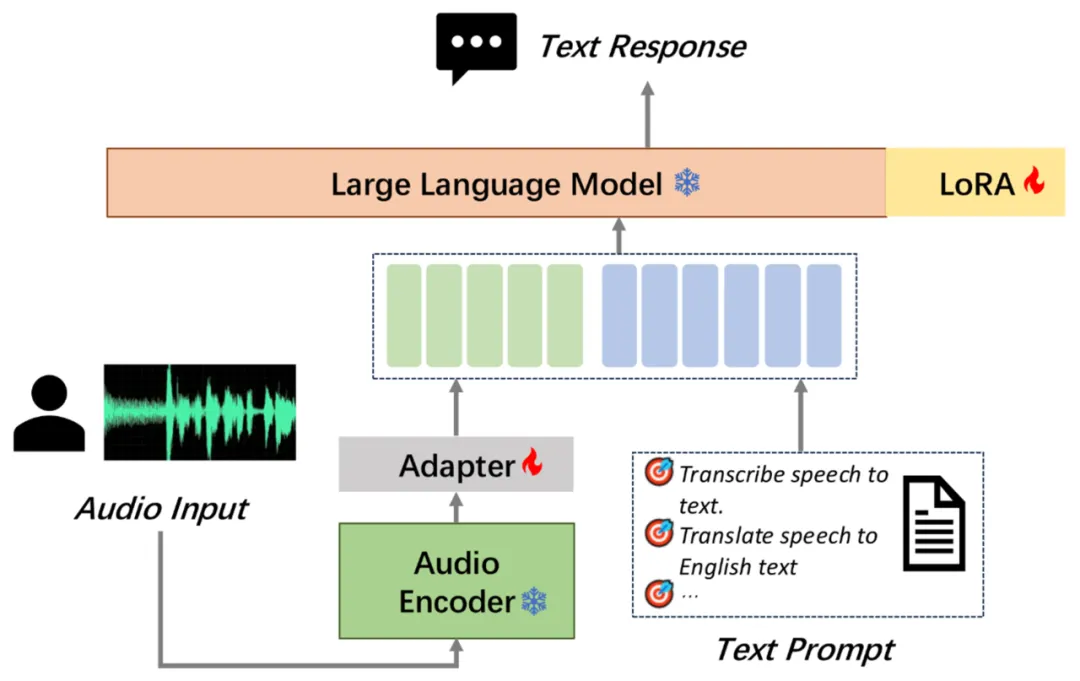
摩尔线程开源了音频理解大模型MooER,支持中英文语音识别和中译英语音翻译。MooER-5K在测试中表现优异,特别是在Covost2中译英测试集上,BLEU分数达到25.2。模型结构包括Encoder、Adapter和Decoder三个部分。训练过程中使用了自研的夸娥智算平台和DeepSpeed框架。MooER与其他开源模型相比效果更优。文章提供了一些有关Encoder选择、音频建模粒度和快速适应到目标垂类的建议。
多模态大模型能同时处理多种形式数据输入输出,学习不同模态之间的关联和映射关系,发现隐藏在数据中的复杂跨模态模式。目前在图片理解方面效果较好,但在视频和音频理解方面仍有待改进。多模态大模型整体处于发展阶段,但在垂直场景下已能做出一些之前做不到或做不好的应用。
多模态大模型能够处理图像、视频和音频等多种数据输入,通过编码、投影和解码层实现不同模态的特征对齐和理解。目前主流模型如GPT-4o和Gemini在图像和视频理解方面表现良好,但在特定领域仍有差距。视频理解主要通过提取帧进行分析,音频理解也在不断提升,未来有望在垂直场景中实现更高效的应用。
本文介绍了Qwen-Audio模型,旨在提升音频理解能力,覆盖30多项任务和多种音频类型。通过多任务训练框架,Qwen-Audio在多个基准任务中表现优异,且无需特定任务微调。此外,基于此模型开发了Qwen-Audio-Chat,实现多轮对话,支持多种音频场景。
本研究提出了多个AI系统和模型,包括CompA、AudioGPT和GAMA,旨在提升音频理解、组合推理和情感识别能力。通过改进训练方法和引入新基准(如AIR-Bench),研究揭示了现有模型的局限性,并推动了多模态AI的发展。
完成下面两步后,将自动完成登录并继续当前操作。