
NVIDIA 和马里兰大学发布 Audio Flamingo Next (AF-Next):一个功能强大且开放的大型音频语言模型
内容提要
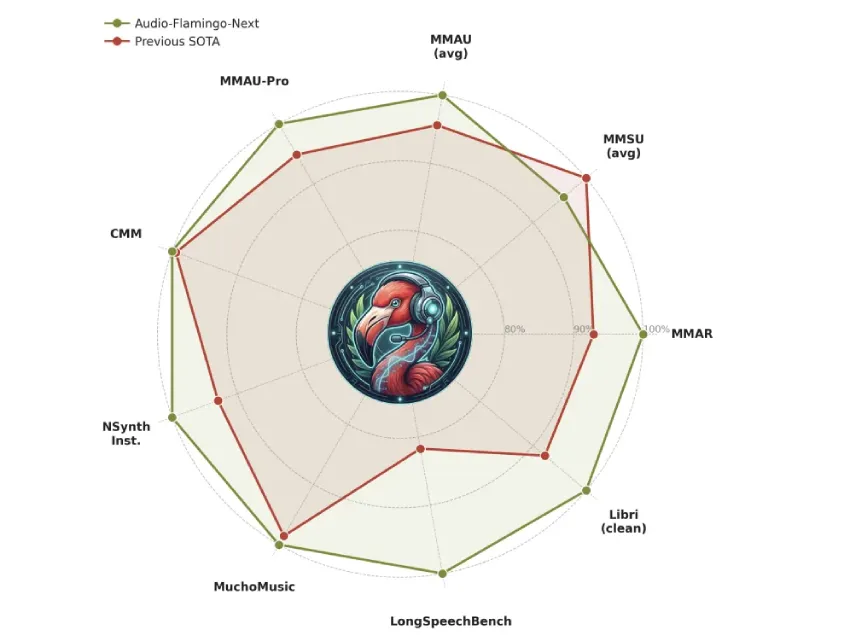
NVIDIA与马里兰大学推出了Audio Flamingo Next(AF-Next),这是一个开放的大型音频语言模型,旨在提升音频理解能力。AF-Next有三种版本,分别用于问答、多步骤推理和音频字幕生成。该模型通过时间音频思维链技术,能够更准确地处理长达30分钟的录音,并在长音频理解和音乐识别方面表现优异。
关键要点
-
NVIDIA与马里兰大学推出了Audio Flamingo Next (AF-Next),这是一个开放的大型音频语言模型,旨在提升音频理解能力。
-
AF-Next提供三种版本,分别用于问答(AF-Next-Instruct)、多步骤推理(AF-Next-Think)和音频字幕生成(AF-Next-Captioner)。
-
AF-Next通过时间音频思维链技术,能够更准确地处理长达30分钟的录音,提高长音频理解和音乐识别的能力。
-
AF-Next的训练数据集包含约1.08亿个样本和约100万小时的音频,涵盖多种音频类型和任务。
-
在各项基准测试中,AF-Next在音频推理、音乐理解和长音频理解方面均表现优异,超越了之前的模型和闭源对手。
延伸解读
音频理解的技术突破
AF-Next通过时间音频思维链技术,显著提升了长音频的理解能力。这一方法将推理步骤与音频时间戳相结合,使得模型在处理复杂音频时更具可解释性,解决了以往模型在长音频推理中的局限性。
多样化的应用场景
AF-Next提供三种专用版本,分别针对问答、多步骤推理和音频字幕生成。这种灵活性使得用户可以根据具体需求选择合适的模型,避免了单一模型无法满足多样化任务的情况。
训练数据的规模与多样性
AF-Next的训练数据集包含约1.08亿个样本和100万小时的音频,涵盖多种音频类型。这种大规模、多样化的数据为模型的性能提升提供了坚实基础,尤其是在音频推理和音乐理解方面。
延伸问答
Audio Flamingo Next (AF-Next) 的主要功能是什么?
AF-Next 是一个开放的大型音频语言模型,旨在提升音频理解能力,提供问答、多步骤推理和音频字幕生成等功能。
AF-Next 有哪些不同的版本?
AF-Next 提供三种版本:AF-Next-Instruct(问答)、AF-Next-Think(多步骤推理)和 AF-Next-Captioner(音频字幕生成)。
AF-Next 如何处理长达30分钟的录音?
AF-Next 通过时间音频思维链技术,将中间推理步骤锚定到音频时间戳,从而提高长音频理解的准确性。
AF-Next 的训练数据集包含多少音频样本?
AF-Next 的训练数据集包含约1.08亿个样本和约100万小时的音频。
AF-Next 在音频推理基准测试中的表现如何?
AF-Next 在音频推理基准测试 MMAU-v05.15.25 中,AF-Next-Instruct 的平均准确率达到 74.20%,超越了之前的模型。
AF-Next 的架构包含哪些主要组件?
AF-Next 由 AF-Whisper 音频编码器、音频适配器、LLM骨干网络和流式 TTS 模块四个主要组件构成。
