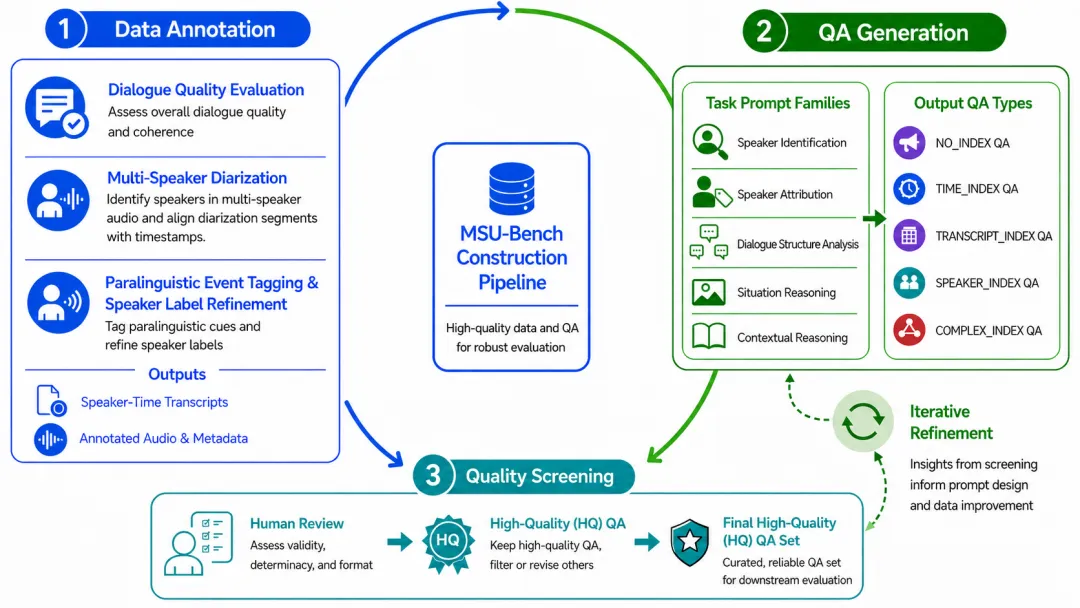
音频语言模型(ALMs)推动语音理解向多任务生成转型。西工大与南京大学等合作提出MSU-Bench评测基准,专注于多说话人对话理解,涵盖16个子任务。研究表明,现有模型在说话人定位和对话推理方面仍存在不足,未来需优化以提升多说话人理解能力。
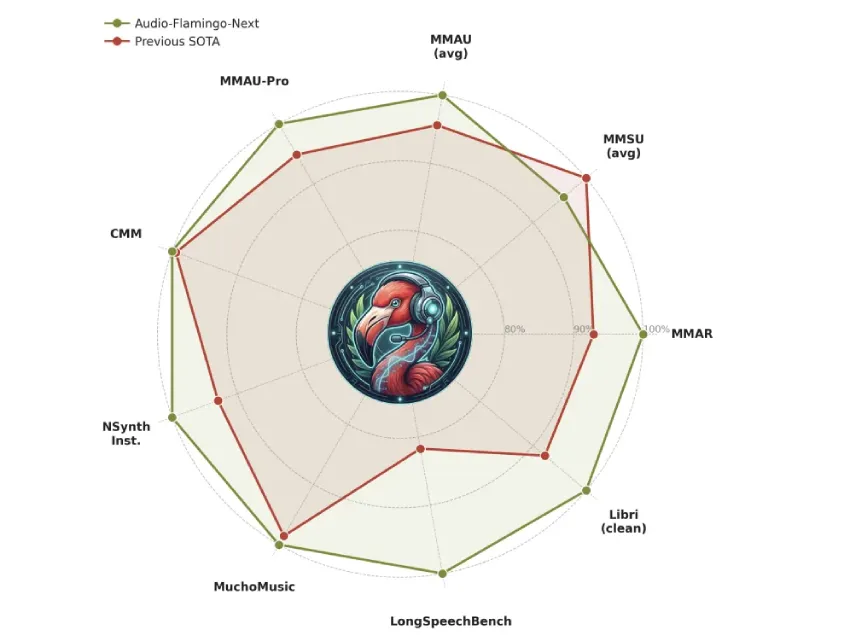
NVIDIA与马里兰大学推出了Audio Flamingo Next(AF-Next),这是一个开放的大型音频语言模型,旨在提升音频理解能力。AF-Next有三种版本,分别用于问答、多步骤推理和音频字幕生成。该模型通过时间音频思维链技术,能够更准确地处理长达30分钟的录音,并在长音频理解和音乐识别方面表现优异。
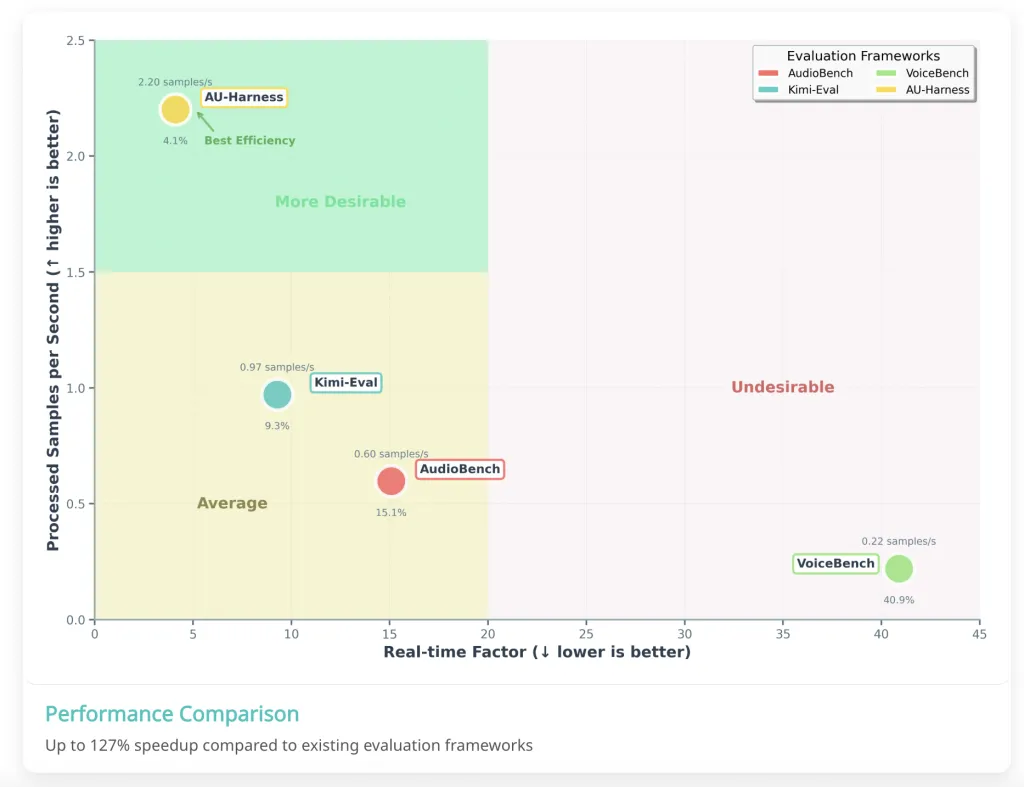
德克萨斯大学与ServiceNow推出AU-Harness,旨在高效评估大型音频语言模型,支持多种任务,提升评估速度与灵活性,解决现有基准测试的不足。
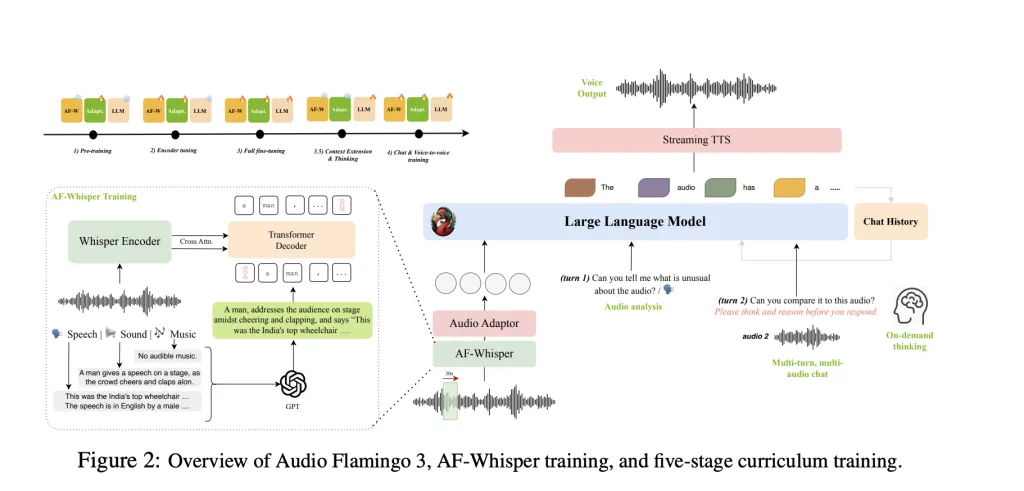
NVIDIA推出的Audio Flamingo 3(AF3)是一个开源的大型音频语言模型,具备理解和推理音频的能力,支持最长10分钟的音频输入,能够进行多轮对话和思维链推理,显著提升音频处理的准确性和效率,表现优异,推动通用音频智能的发展。
本研究创建了AJailBench,评估大型音频语言模型(LAMs)在越狱攻击下的安全性。结果表明,现有LAM在面对精心设计的音频攻击时存在明显脆弱性,强调了开发更强大防御机制的必要性。
本文探讨了大型音频语言模型的越狱攻击,指出现有文本攻击的不足,并提出了一种新方法AudioJailbreak,具有异步性、普遍性、隐蔽性和抗干扰性,能有效提升模型安全性。
vLLM是一个专为大语言模型推理加速设计的框架,解决了内存管理瓶颈,实现了KV缓存内存几乎零浪费。它支持音频语言模型的离线推理,并提供多种模型的使用示例,适用于不同的音频输入。
本研究提出了极长音频基准(BLAB),用于评估音频语言模型在长音频段的理解能力。通过对833小时音频的评估,发现现有模型在定位和时长估计等任务中的表现不佳,揭示了任务难度与音频时长之间的权衡关系。
本研究探讨了音频大型语言模型在真实环境中的听觉认知能力,提出了五种测试时间计算方法,以提升模型在复杂任务中的表现,为助听器和语音助手等应用的发展奠定基础。
本研究提出了AdvWave框架,旨在提高大型音频语言模型的安全性,防止越狱攻击。通过双阶段优化和适应性对抗目标搜索,AdvWave在多个模型上实现了比基线方法高出40%的攻击成功率,具有重要应用价值。
本研究提出了NatureLM-audio音频语言基础模型,旨在解决生物声学中的动物声音检测、稀有物种分类及行为标签问题。该模型通过多样化的文本-音频配对训练数据,推动了生物声学领域的研究进展。
本研究探讨了大型音频语言模型在理解音频和语言信息时的幻觉问题。通过三个评估任务,发现模型在识别声音事件、确定事件顺序和识别声音来源方面存在局限性。引入多轮链式思维方法后,模型表现有所提升。
本文探讨了多种音频语言模型的进展,包括Mockingjay、wave2vec2.0和Qwen-Audio等。这些模型在语音理解、文本到音频生成及多轮对话方面表现优异,尤其是Qwen-Audio通过多任务训练框架显著提升了音频理解能力。此外,AIR-Bench基准为评估音频模型的交互能力提供了新方法,推动了该领域的发展。
本研究解决了深度伪音频检测中的关键问题,即对基于音频语言模型(ALM)生成的音频的有效性。通过收集和评估12种最新的ALM深度伪音频,研究发现最新的编码训练反制措施在大多数ALM测试条件下实现了0%的误差率,展示了ALM深度伪音频检测的新前景。
Qwen2-Audio是新发布的多模态音频语言模型,支持语音指令和音频分析,能够处理超过8种语言。该模型在语音聊天、音频分析和多语言支持方面表现优异,未来将进行更大规模的训练以提升性能。
完成下面两步后,将自动完成登录并继续当前操作。