
AU-Harness:用于音频 LLM 整体评估的开源工具包
内容提要
德克萨斯大学与ServiceNow推出AU-Harness,旨在高效评估大型音频语言模型,支持多种任务,提升评估速度与灵活性,解决现有基准测试的不足。
关键要点
-
德克萨斯大学与ServiceNow推出AU-Harness,旨在高效评估大型音频语言模型。
-
现有的音频基准测试存在碎片化、缓慢和侧重点狭窄的问题。
-
AU-Harness是一个开源工具包,支持快速、标准化和可扩展的评估。
-
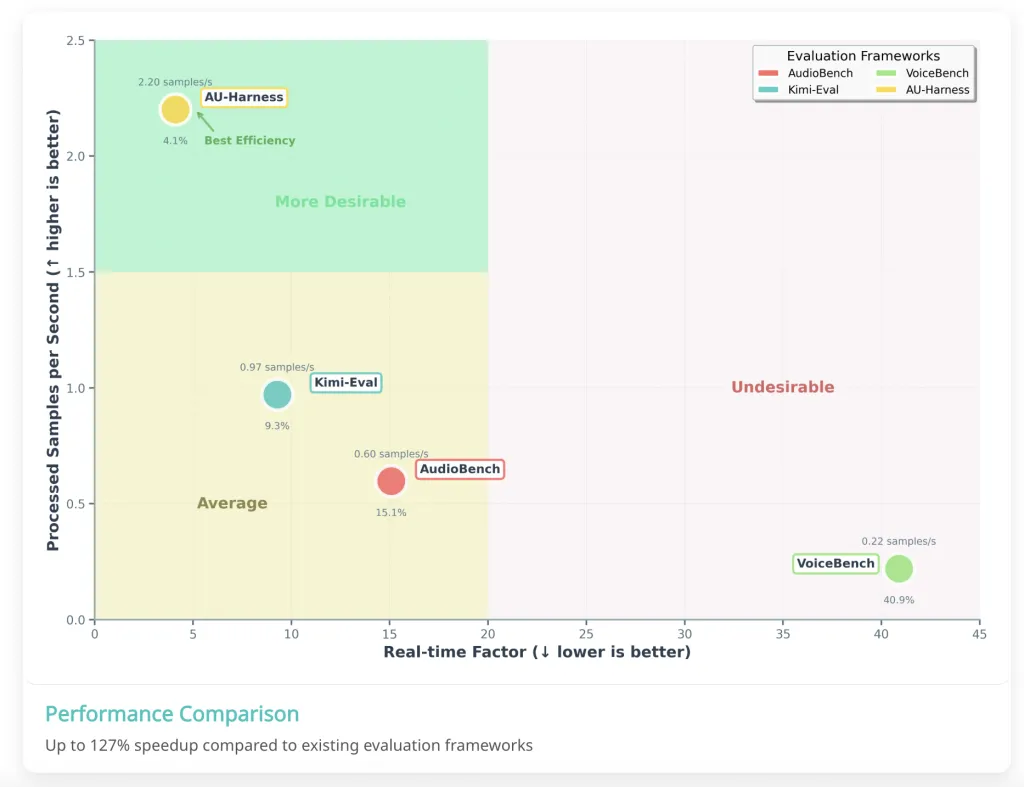
AU-Harness通过与vLLM推理引擎集成,提高了评估的吞吐量和效率。
-
AU-Harness允许灵活配置评估参数,支持多轮对话评估。
-
AU-Harness支持50多个数据集和21个任务,涵盖语音识别、音频理解等多个领域。
-
AU-Harness揭示了当前模型在时间推理和复杂指令执行方面的不足。
-
AU-Harness的推出标志着音频语言模型评估向标准化和可扩展性迈出了重要一步。
延伸解读
音频模型评估的必要性
随着语音AI技术的快速发展,现有的评估工具未能跟上其进步,导致模型比较和多轮测试变得困难。AU-Harness的推出,正是为了填补这一空白,提供一个高效、标准化的评估框架,帮助研究人员更好地理解和优化音频语言模型的性能。
AU-Harness的灵活性与扩展性
AU-Harness不仅支持多种任务和数据集,还允许研究人员灵活配置评估参数。这种灵活性使得针对特定需求的评估成为可能,尤其是在多轮对话场景中,能够更准确地反映模型的实际表现。
当前模型的局限性
尽管AU-Harness在评估效率上有显著提升,但测试结果显示,当前模型在时间推理和复杂指令执行方面仍存在不足。这提示研究人员在开发新模型时,需要关注这些关键领域,以提升模型在真实应用中的表现。
延伸问答
AU-Harness的主要功能是什么?
AU-Harness是一个开源工具包,旨在高效评估大型音频语言模型,支持快速、标准化和可扩展的评估。
AU-Harness如何解决现有音频基准测试的问题?
AU-Harness通过提高评估的吞吐量和效率,解决了现有基准测试的碎片化、缓慢和侧重点狭窄的问题。
AU-Harness支持哪些类型的任务?
AU-Harness支持50多个数据集和21个任务,包括语音识别、音频理解、口语理解和口语推理等。
AU-Harness如何提高评估效率?
AU-Harness通过与vLLM推理引擎集成,采用基于令牌的请求调度程序和数据集分片,显著提高了评估效率。
AU-Harness在多轮对话评估方面有什么特点?
AU-Harness支持多轮对话评估,允许研究人员测试对话连续性、语境推理和适应性。
AU-Harness揭示了当前模型的哪些不足之处?
AU-Harness揭示了模型在时间推理和复杂指令执行方面的不足,尤其是在处理音频指令时表现较差。
