
通过Foundry,微软押注企业AI的竞争在于可靠性,而非能力
The New Stack
·
【公益译文】2026年AI指数报告(三)
绿盟科技技术博客
·


推出Agent Interop评估入门工具包
Microsoft 365 Developer Blog
·


介绍Evalite:面向AI应用的TypeScript测试工具
InfoQ
·

Ai2的Olmo 3推动开源大型语言模型性能的极限
The New Stack
·
评估工具如何推动企业人工智能的下一个篇章
OpenAI
·

为AI代理准确性构建定制化的LLM评估者
Databricks
·
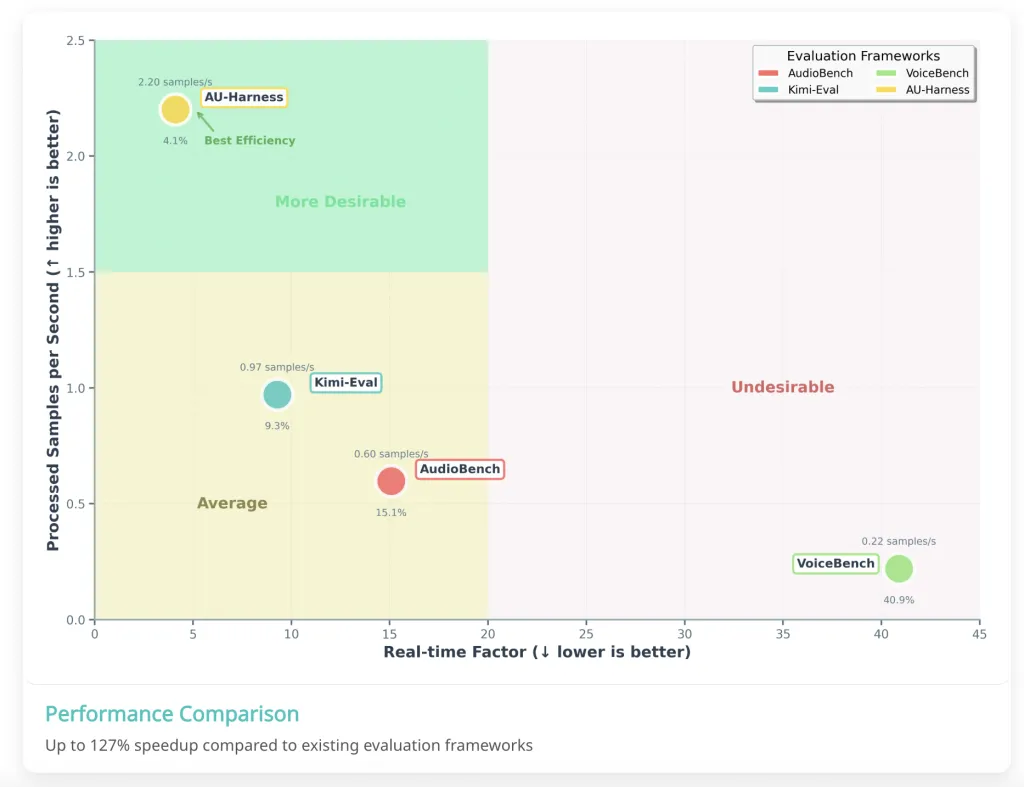
AU-Harness:用于音频 LLM 整体评估的开源工具包
实时互动网
·

SafeLine WAF与Cloudflare和ModSecurity的真实基准测试与数据
DEV Community
·
