
基于Spark的1996-2022多赛季NBA球员数据分析
原文中文,约22300字,阅读约需54分钟。
📝
内容提要
本文介绍了基于Python和Spark的NBA球员数据分析项目,包括实验环境和数据准备步骤,使用Spark进行数据分析,以及使用Plotly库进行数据可视化和Flask搭建本地Web服务器展示可视化结果。
🎯
关键要点
-
本文介绍了基于Python和Spark的NBA球员数据分析项目。
-
实验环境包括Linux Mint、Hadoop、Spark、Python等。
-
数据集来自Kaggle,包含1996至2022年NBA球员的多项数据。
-
数据预处理包括创建新列、转换数据类型和标准化国家名称。
-
项目框架包括数据预处理、数据分析和可视化。
-
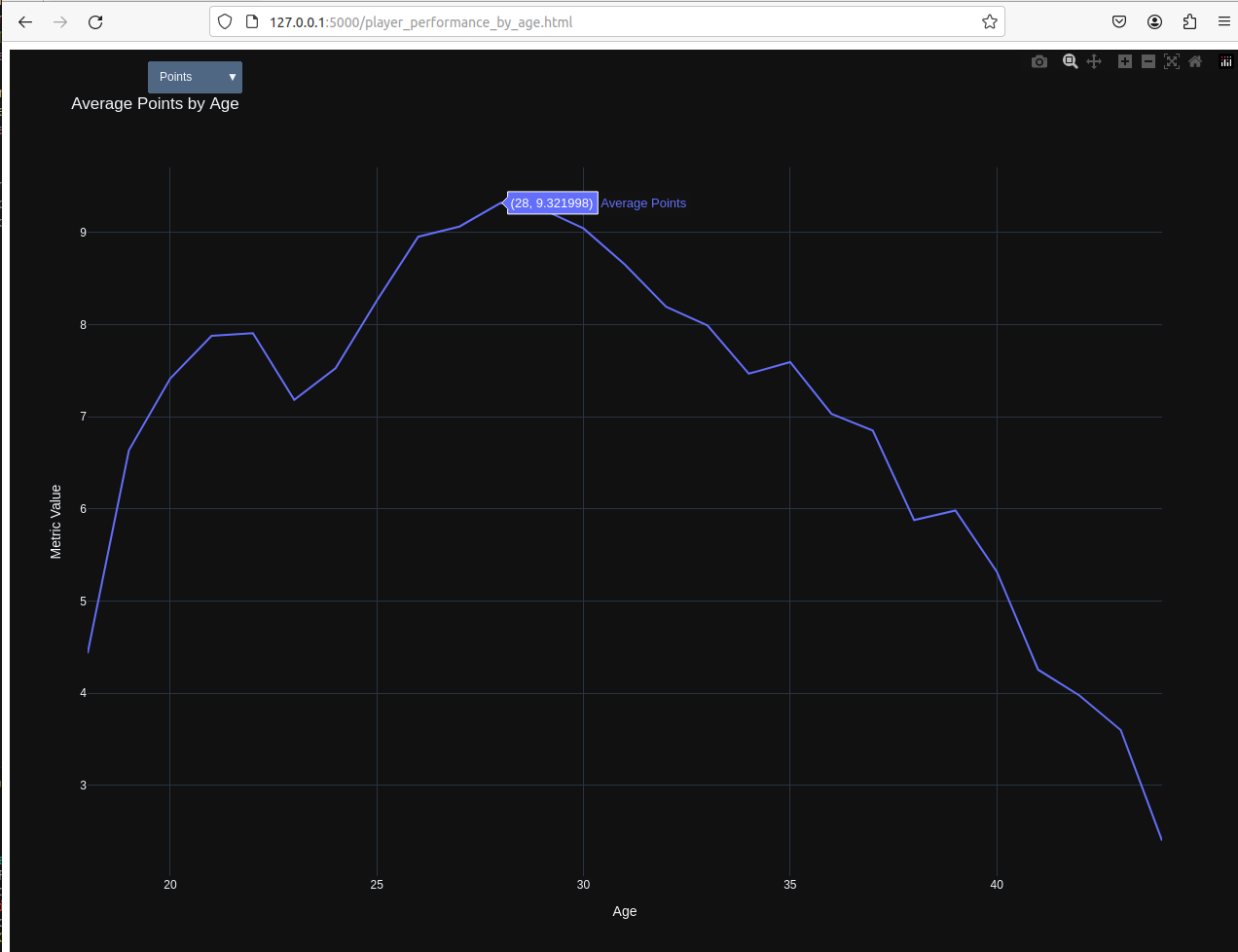
使用Spark进行数据分析,分析问题包括球员年龄对得分的影响等。
-
数据分析结果以JSON格式保存,并从HDFS取回。
-
使用Plotly库进行数据可视化,生成多个HTML文件。
-
Flask框架用于搭建本地Web服务器展示可视化结果。
-
可视化结果包括球员表现、大学表现和国际球员比例等分析。
❓
延伸问答
这篇文章使用了哪些技术进行NBA球员数据分析?
文章使用了Python和Spark进行NBA球员数据分析,结合Flask搭建Web服务器和Plotly进行数据可视化。
数据集包含哪些NBA球员的基本信息?
数据集包含球员姓名、球队缩写、年龄、身高、体重、大学、出生国家、选秀年份、比赛次数、场均得分等21个属性。
如何处理NBA球员数据中的缺失值?
文章中使用了布尔逻辑创建新列,替换缺失值,并将某些列转换为日期类型,以便进行后续分析。
文章中分析了哪些球员表现的影响因素?
分析了球员年龄对得分、助攻和篮板的影响,以及身高、体重与场均助攻和篮板之间的相关性。
如何使用Flask展示数据可视化结果?
使用Flask框架搭建本地Web服务器,通过渲染HTML模板展示可视化结果,用户可以通过链接访问不同的统计图。
国际球员在NBA中的占比变化如何?
文章指出,国际球员在NBA中的占比在过去几十年中稳步上升,显示出联盟的国际化成功。
🏷️
