
从裸机到70B大模型②:基础设施设置与脚本
原文中文,约15900字,阅读约需38分钟。
📝
内容提要
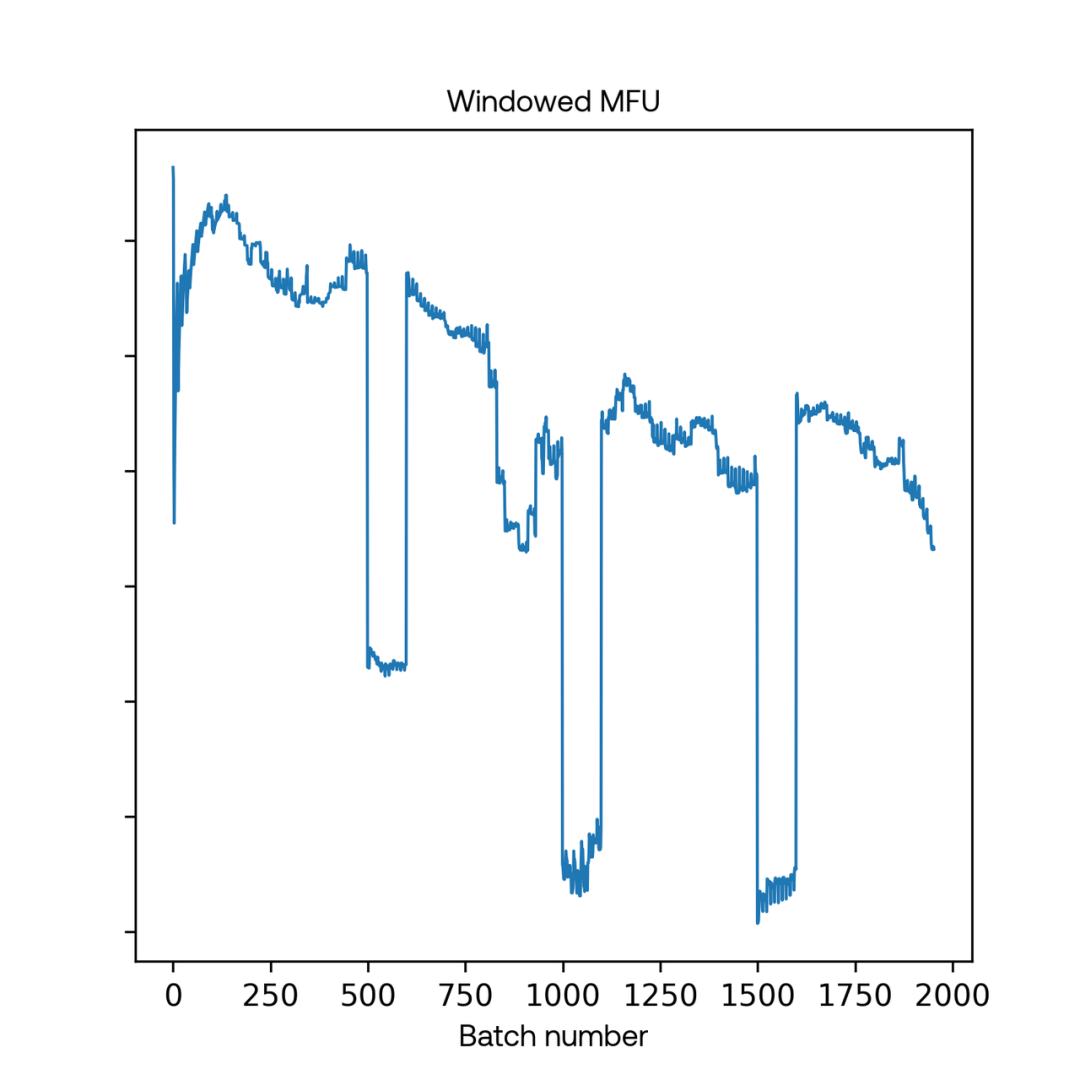
Imbue团队成功训练了一个70亿参数的大模型,分享了集群配置、GPU通信、故障诊断和健康检查等经验,强调了自动化和稳定性在高效模型训练中的重要性。
🎯
关键要点
-
Imbue团队成功训练了一个70亿参数的大模型,强调了基础设施的重要性。
-
集群由511台服务器组成,部署了4088枚H100 GPU,确保高速数据通信。
-
使用InfiniBand网络实现完全非阻塞的通信,提升训练效率。
-
开发了多种基础设施脚本,确保主机健康和自动化故障诊断。
-
在训练过程中遇到的挑战包括机器故障、网络问题和GPU配置错误。
-
实施了健康检查程序,确保机器能够稳定运行并进行训练。
-
构建了本地文件系统和Docker注册表,以提高数据传输效率。
-
总结了在基础设施建设中的经验教训,强调了自动化和稳定性的重要性。
❓
延伸问答
Imbue团队是如何成功训练70亿参数的大模型的?
Imbue团队通过构建由511台服务器和4088枚H100 GPU组成的集群,利用InfiniBand网络实现高速数据通信,确保了模型训练的高效性。
在训练过程中,Imbue团队遇到了哪些主要挑战?
主要挑战包括机器故障、网络问题和GPU配置错误,这些问题影响了训练的稳定性和效率。
Imbue团队如何确保集群的健康和稳定运行?
团队开发了多种基础设施脚本和健康检查程序,以自动化故障诊断和确保主机健康,提升集群的稳定性。
InfiniBand网络在Imbue团队的集群中起到了什么作用?
InfiniBand网络提供了完全非阻塞的通信,确保了GPU之间的高速数据传输,从而提升了训练效率。
Imbue团队在基础设施建设中总结了哪些经验教训?
团队强调了自动化和稳定性的重要性,建议在训练运行中保留额外的机器以应对故障,并开发工具以简化问题诊断。
Imbue团队如何处理GPU的故障和性能问题?
团队通过自动化检查和重新配置GPU,确保每台机器能够独立处理真实的GPU工作负载,并及时解决硬件问题。
🏷️
