
从 Kubernetes 到 Qwen:AI 时代的“开源”为何变了?
内容提要
文章探讨了AI时代开源的变革,指出中美厂商在开源策略上的差异:美国公司倾向于闭源以保持竞争力,而中国厂商则通过开源建立生态。开源的核心已从源码转向模型权重和微调能力,强调赋能开发者。
关键要点
-
文章探讨了AI时代开源的变革,指出中美厂商在开源策略上的差异。
-
美国公司倾向于闭源以保持竞争力,而中国厂商通过开源建立生态。
-
开源的核心已从源码转向模型权重和微调能力,强调赋能开发者。
-
云原生时代的开源逻辑与AI大模型时代的开源逻辑截然不同。
-
美国科技公司选择闭源的原因包括商业逻辑、算力与数据不可复制、安全与合规约束。
-
中国公司更愿意开源的原因包括用开源换生态、灵活的数据政策和国家战略驱动。
-
开源载体从GitHub转移到Hugging Face,核心资产的开源形态发生变化。
-
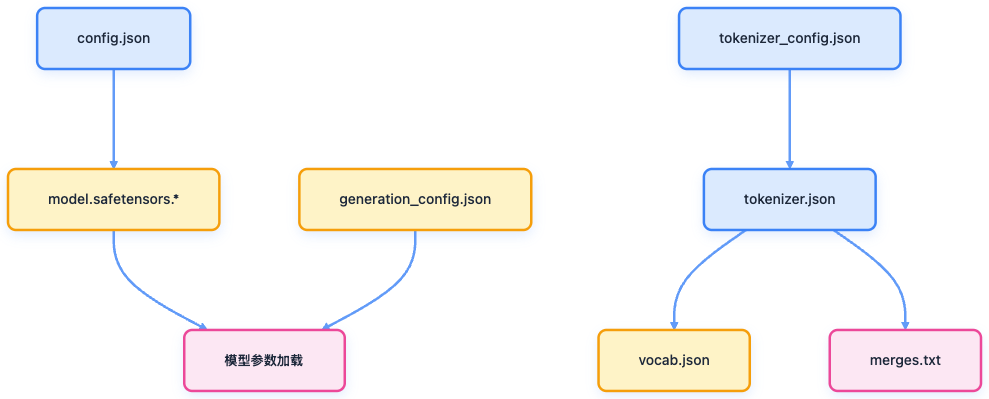
AI时代的开源不仅包括代码开放,还包括权重、推理代码和微调能力。
-
企业倾向于自部署开源模型的原因包括数据隐私、成本可控性和可定制性。
-
开源模型的生命周期包括下载模型权重、加载推理代码、微调和上线生产环境。
-
开源大模型的许可证决定了是否可以商用,需关注许可证信息。
延伸解读
中美开源策略的根本差异
美国公司在AI时代倾向于闭源,主要是为了保护其商业竞争力和核心技术。而中国公司则通过开源来建立生态,快速提升品牌影响力。这种策略差异反映了两国在技术发展和市场环境上的不同考量,值得关注。
开源模型的核心要素
AI时代的开源不仅仅是代码的开放,更重要的是模型权重、推理代码和微调能力的共享。这些要素使得开发者能够更灵活地应用和定制模型,推动了技术的普及和创新。
自部署的优势
企业选择自部署开源模型的原因包括数据隐私保护、成本控制和可定制性等。这种选择不仅能提高数据安全性,还能根据企业的具体需求进行优化,增强了模型的实用性。
延伸问答
AI时代开源的核心要素是什么?
AI时代的开源核心要素包括开放权重、推理代码和微调能力。
中美厂商在开源策略上有什么主要差异?
美国公司倾向于闭源以保持竞争力,而中国厂商则通过开源建立生态。
为什么中国公司更愿意开源?
中国公司更愿意开源是因为用开源换生态、灵活的数据政策和国家战略驱动。
企业选择自部署开源模型的原因是什么?
企业选择自部署开源模型的原因包括数据隐私、成本可控性和可定制性。
开源大模型的生命周期包括哪些步骤?
开源大模型的生命周期包括下载模型权重、加载推理代码、微调和上线生产环境。
如何判断开源大模型的许可证?
判断开源大模型的许可证可以查看Hugging Face模型主页的License信息或仓库根目录下的LICENSE文件。
