
国产芯片上跑出的万亿参数模型,美团 LongCat-2.0 正式发布
内容提要
美团发布了新一代万亿参数大模型LongCat-2.0,并将其开源。该模型在国产算力集群上完成全流程训练,支持1M超长上下文,专注于代码理解与生成,表现优异,成为全球开发者的热门选择。
关键要点
-
美团发布了新一代万亿参数大模型LongCat-2.0,并将其开源。
-
LongCat-2.0在国产算力集群上完成全流程训练,支持1M超长上下文,专注于代码理解与生成。
-
该模型的预训练数据规模超过30T tokens,涵盖多种语言和代码数据。
-
LongCat-2.0采用稀疏注意力机制,能够在处理超长上下文时保持信息定位与理解能力。
-
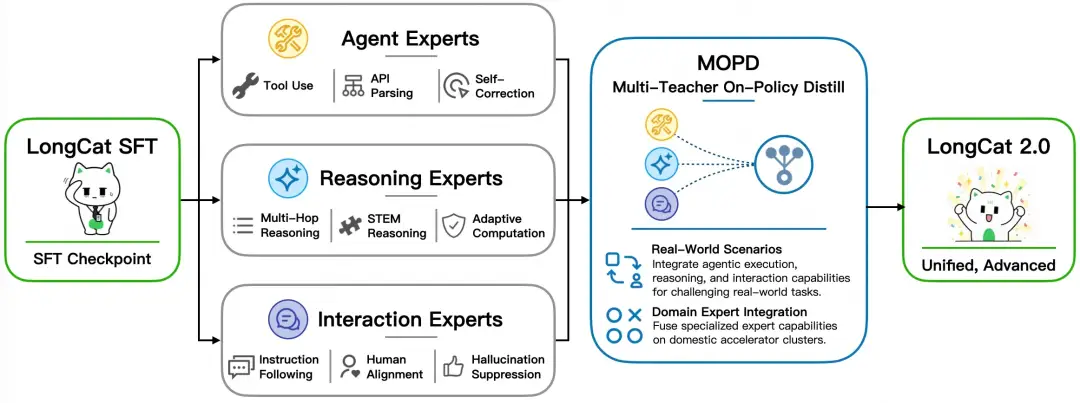
模型通过零计算专家和多专家融合架构,优化了算力使用,提高了编程、推理和交互能力。
-
在编程能力评测中,LongCat-2.0表现优异,领先于多个竞争模型。
-
在真实办公场景的复杂任务处理方面,LongCat-2.0也展现出高可靠性,满足企业级需求。
延伸解读
国产算力的突破与挑战
LongCat-2.0在国产算力集群上完成训练,标志着国内在大规模模型训练方面的重大进展。然而,尽管技术上取得了突破,仍需关注算力资源的稳定性和可靠性,尤其是在面对硬件故障和通信异常时,如何保持训练和推理的高效性仍是一个挑战。
超长上下文处理的优势
LongCat-2.0支持1M超长上下文,采用稀疏注意力机制,使得模型在处理长文本时能够有效筛选关键信息。这一设计不仅提升了信息处理的效率,也为复杂代码理解和生成任务提供了更强的支持,适合需要处理大量上下文信息的开发场景。
多专家融合架构的创新
LongCat-2.0通过多专家融合架构,针对不同任务动态调度最适合的专家,提升了模型在编程、推理和交互等方面的表现。这种灵活的架构设计使得模型能够在多样化的应用场景中展现出更高的适应性和效率,值得开发者关注其在实际应用中的表现。
延伸问答
LongCat-2.0的主要特点是什么?
LongCat-2.0是一款万亿参数大模型,支持1M超长上下文,专注于代码理解与生成,并在国产算力集群上完成全流程训练。
LongCat-2.0是如何处理超长上下文的?
LongCat-2.0采用稀疏注意力机制,能够在处理超长上下文时保持信息定位与理解能力,计算量从平方级降至线性级。
LongCat-2.0在编程能力评测中表现如何?
在编程能力评测中,LongCat-2.0在SWE-bench Pro中获得59.5分,领先多个竞争模型,展现出扎实的综合实力。
LongCat-2.0的预训练数据规模有多大?
LongCat-2.0的预训练数据规模超过30T tokens,涵盖多种语言和代码数据。
LongCat-2.0的架构设计有什么优势?
LongCat-2.0的架构设计围绕高效稳定的代码理解与生成,结合零计算专家和多专家融合架构,优化了算力使用。
LongCat-2.0在企业级应用中表现如何?
LongCat-2.0在真实办公场景的复杂任务处理方面表现均衡,能够满足企业级需求,展现出高可靠性。
