
用多模态技术在多媒体系统中实现场景分类
内容提要
本文研究了多模态算法在多媒体系统中进行视频场景分类的应用,通过识别单帧图像特征进行分类。clip和blip是两种经典的多模态算法,能够处理图像和文本数据,并在多种任务上展现出卓越性能。实验结果表明,基于clip的方案在准确率和性能上优于传统算法。未来,多媒体实验室将继续探索引入更多大模型和多模态技术,提高整个系统的性能。
关键要点
-
视频场景分类算法是计算机视觉领域的热门研究内容,应用于多媒体实验室的多项业务。
-
多模态技术结合图像、文本、音频等多种数据类型,提高了模型的泛化能力。
-
传统图像分类方法需要大量手工调整和参数优化,性能有限。
-
深度学习技术的快速发展使得CNN成为一种有效的图像分类模型。
-
多模态算法能够处理多种模态数据,扩展了人工智能的应用潜力。
-
clip和blip是两种经典的多模态算法,具有强大的跨模态理解能力。
-
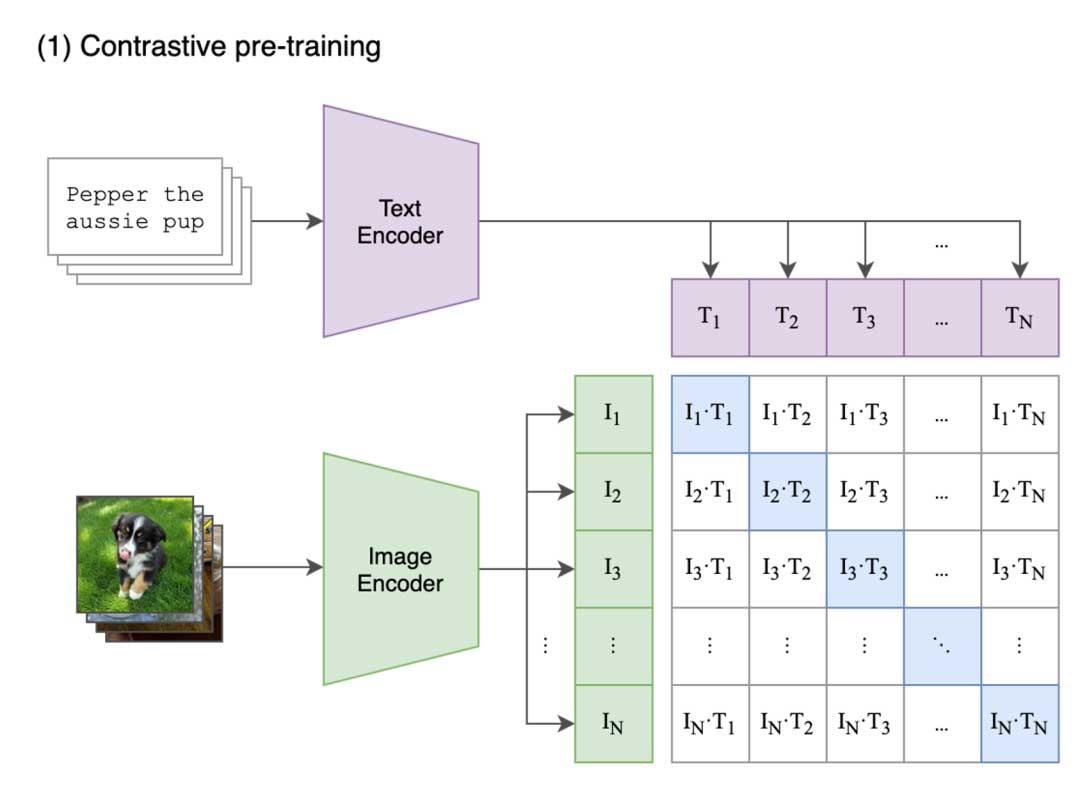
clip通过对比学习将图像和文本映射到共享的多模态向量空间。
-
blip是一个统一视觉语言理解生成的预训练框架,适应更广泛的下游任务。
-
视频分类系统结合场景切分技术和图像分类技术,提高了分类效率。
-
基于clip的方案在准确率和性能上优于传统算法,适用于实际业务需求。
-
未来多媒体实验室将继续探索引入更多大模型和多模态技术,提升系统性能。
延伸问答
多模态技术在视频场景分类中有什么应用?
多模态技术结合图像、文本和音频等多种数据类型,提高了视频场景分类的准确性和效率。
clip和blip算法有什么区别?
clip通过对比学习将图像和文本映射到共享的多模态向量空间,而blip则是一个统一视觉语言理解生成的预训练框架,适应更广泛的下游任务。
传统图像分类方法的局限性是什么?
传统方法通常需要大量手工调整和参数优化,且在处理大规模数据集时性能有限。
如何提高视频分类系统的效率?
通过结合场景切分技术和图像分类技术,可以高效地对视频内容进行分类,满足多样化的应用场景。
clip算法在分类任务中的优势是什么?
clip算法具备强大的跨模态理解能力,能够在零样本任务中表现出色,并且通过设置提示词实现灵活的分类标签。
未来多媒体实验室的研究方向是什么?
未来多媒体实验室将继续探索引入更多大模型和多模态技术,以提升整个系统的性能。
