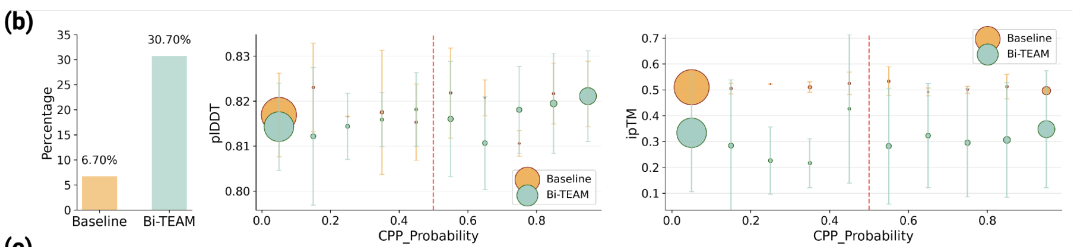
一分钟读论文:《Safety Sentry:上下文感知的三向路由Agent安全审查》
Micropaper
·

残余上下文扩散语言模型
Apple Machine Learning Research
·

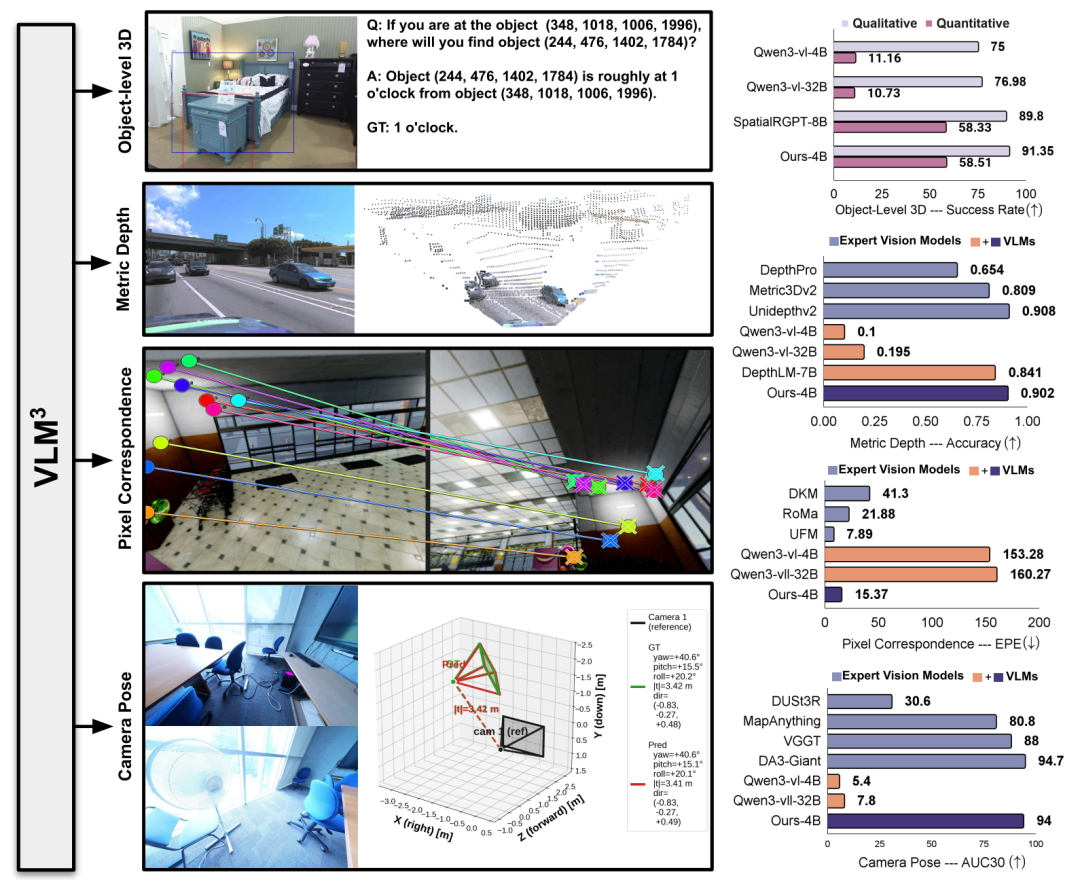
AI 范式雷达:《Agent规划脆弱性——检索受限下大规模工具生态中的长期规划基准测试》
Micropaper
·


一分钟读论文:《重新思考还是延长预算?面向推理预算的选择性验证》
Micropaper
·
【公益译文】2026年AI指数报告(四)
绿盟科技技术博客
·

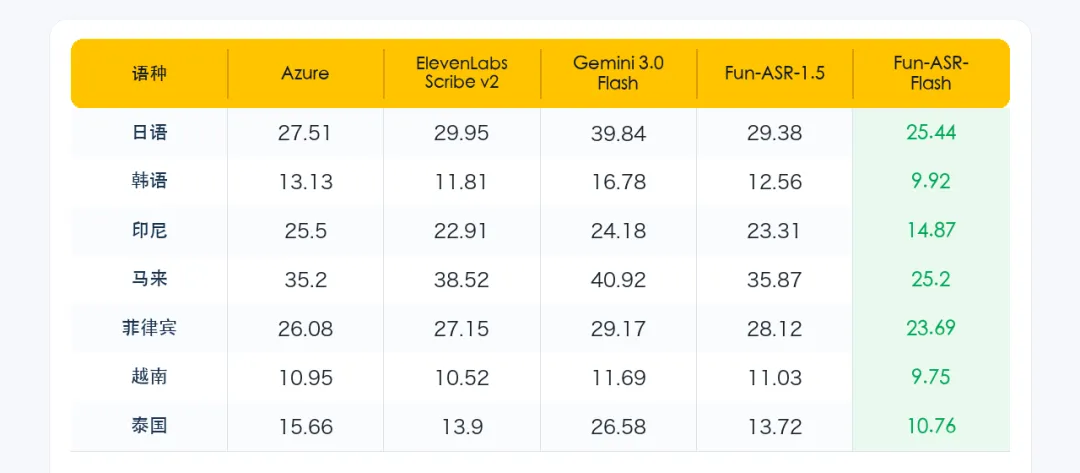
如何提升AI实时语音技术准确率?
实时互动网
·

分析:AI 助手在回答流媒体可用性查询方面表现不一致
实时互动网
·

Databricks将GPT-5.5引入企业代理工作流
OpenAI
·