
深度估计准确率冲上0.9,Meta提出VLM³,论证视觉模型天生会学3D,以Qwen3-VL-4B为基础实现多任务的统一建模
内容提要
三维空间感知是自动驾驶和机器人领域的核心能力,旨在从二维图像恢复真实世界的空间结构。Meta与普林斯顿大学提出的VLM³框架,基于标准视觉语言模型,统一了物体级三维理解和公制深度估计等任务,显著提升了模型在细粒度三维感知中的表现。研究表明,通用视觉语言模型在三维表征能力上超出预期,为三维视觉领域的统一基础模型提供了新依据。
关键要点
-
三维空间感知是自动驾驶、机器人和三维重建等领域的核心能力,旨在从二维图像恢复真实世界的空间结构。
-
视觉语言模型(VLMs)在二维任务上取得显著进展,但在细粒度三维任务中仍难以与专业模型匹敌。
-
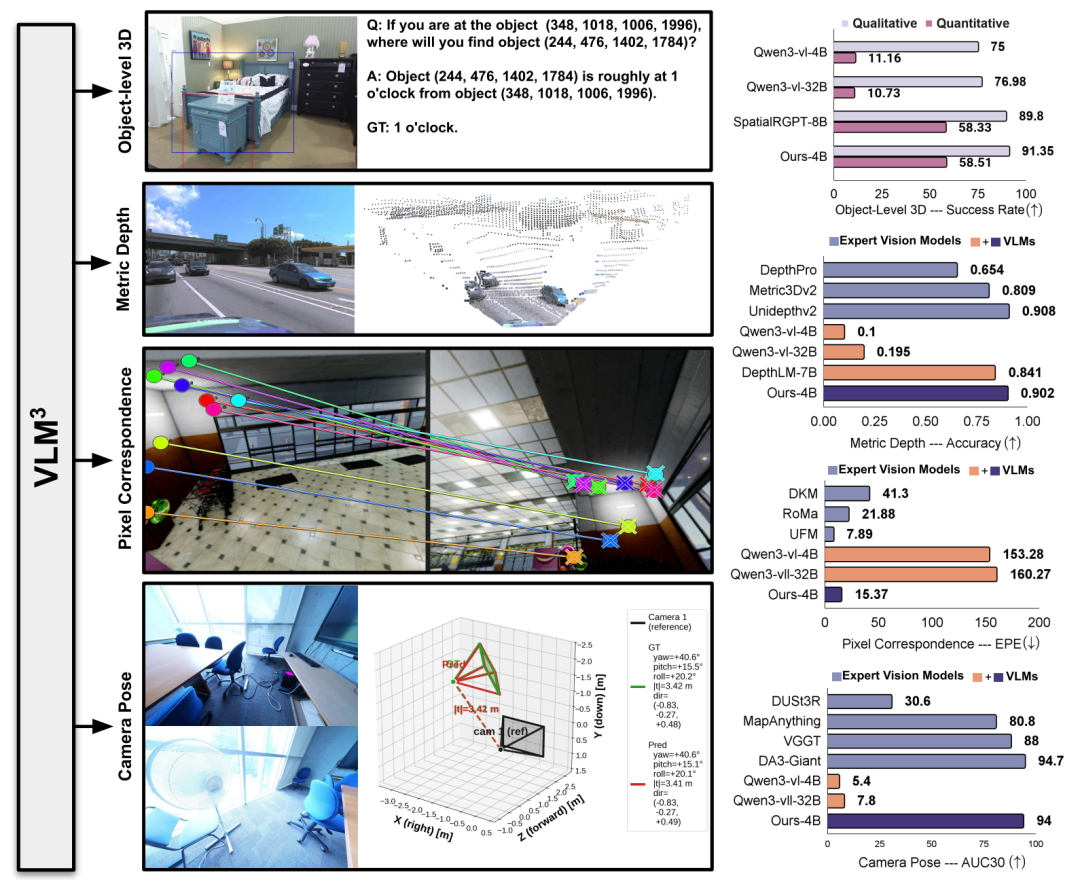
Meta与普林斯顿大学提出的VLM³框架,基于标准视觉语言模型,统一了物体级三维理解和公制深度估计等任务。
-
VLM³在多个评测基准上超越了参数规模更大的模型,显示出其在细粒度三维感知中的强大能力。
-
研究构建了覆盖多种场景的混合数据集,以支持统一三维表征能力的学习。
-
VLM³遵循最小改动原则,优化输入表示、空间定位方式和数据组织策略,未引入额外编码器或专属模块。
-
VLM³在公制深度估计、物体级三维理解、像素匹配和相机位姿估计等任务上实现了统一建模,展现出强大的性能。
-
研究结果表明,通用视觉语言模型的三维表征能力可能超出预期,为三维视觉领域的统一基础模型提供了新依据。
延伸解读
三维空间感知的重要性
三维空间感知在自动驾驶和机器人领域至关重要,它不仅涉及到从二维图像中恢复空间结构,还需要精确的几何推理能力。随着技术的发展,如何提升这一能力成为研究的重点,尤其是在复杂环境下的应用场景中。
VLM³框架的创新之处
VLM³框架通过统一建模实现了多项三维任务的整合,避免了引入额外编码器或复杂模块。这种设计不仅简化了模型结构,还提升了模型在细粒度三维任务中的表现,显示出通用视觉语言模型的潜力。
数据集的重要性与挑战
VLM³的成功依赖于高质量的混合数据集,这些数据集涵盖了多种场景和任务。研究表明,盲目扩大数据规模可能导致性能下降,因此合理配置数据权重和选择训练样本至关重要,以提高模型的泛化能力。
未来研究的方向
VLM³的研究结果为三维视觉领域提供了新的思路,未来可以探索如何进一步优化模型结构和训练策略,以实现更高效的三维感知能力。此外,如何将这一框架应用于实际场景中也是值得关注的方向。
延伸问答
VLM³框架的主要目标是什么?
VLM³框架的主要目标是基于标准视觉语言模型,实现物体级三维理解、公制深度估计、像素匹配和相机位姿估计等任务的统一建模。
VLM³在深度估计任务中的表现如何?
VLM³在深度估计任务中将平均精度δ₁从0.84提升至0.90,性能与专业模型UnidepthV2相当。
VLM³是如何优化输入表示和数据组织的?
VLM³遵循最小改动原则,通过统一图像标准化、文本化空间定位和精细化数据混合策略来优化输入表示和数据组织。
VLM³与传统视觉语言模型相比有什么优势?
VLM³在不引入额外编码器的情况下,利用统一文本定位机制在空间推理任务中表现优于参数规模更大的模型,如SpatialRGPT。
VLM³的训练数据集是如何构建的?
VLM³的训练数据集覆盖多种场景,包含公制深度估计、物体级三维理解等任务,使用了约3200万张图像和3.2亿个深度标注点。
VLM³在像素匹配任务中的表现如何?
VLM³在像素匹配任务中将端点误差降低一个数量级,超过了经典专家模型DKM和RoMa,仅略低于当前最优方法UFM。
