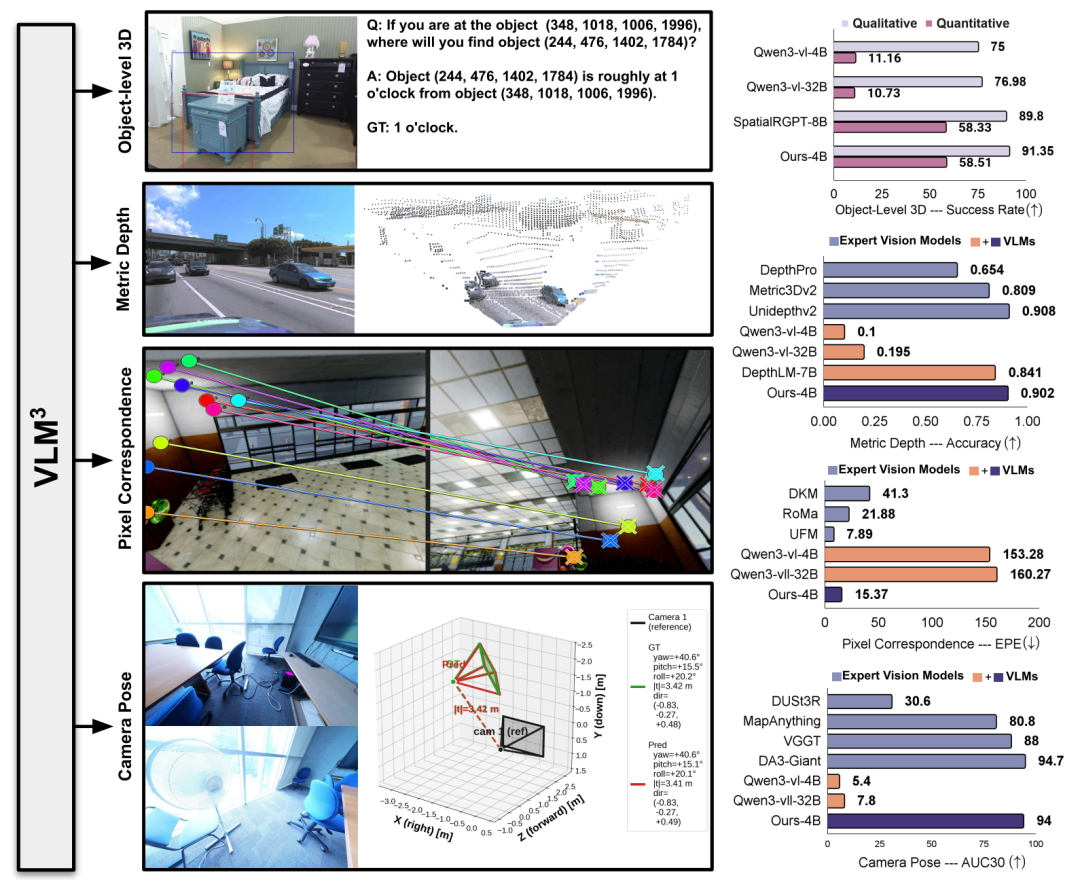
三维空间感知是自动驾驶和机器人领域的核心能力,旨在从二维图像恢复真实世界的空间结构。Meta与普林斯顿大学提出的VLM³框架,基于标准视觉语言模型,统一了物体级三维理解和公制深度估计等任务,显著提升了模型在细粒度三维感知中的表现。研究表明,通用视觉语言模型在三维表征能力上超出预期,为三维视觉领域的统一基础模型提供了新依据。
本研究提出EgoDTM模型,解决自我中心视频语言预训练中缺乏三维理解的问题。该模型结合大规模3D视频预训练与视频-文本对比学习,通过轻量级三维解码器高效学习三维感知。实验结果表明,EgoDTM在多项任务中表现优异,展现出卓越的3D视觉理解能力。
该研究提出了综合连续场景图生成数据集,探索现有方法在学习新对象时的保留情况,并引入新的图卷积网络以解决图像遮挡问题。研究还提出了统一框架OvSGTR和基于因果推断的对象关系预测方法,显著提升了场景图生成性能。此外,开发了图像到文本模型,降低了构建成本,并提出了基于场景图的三维理解方法和开放词汇生成框架。
本文介绍了一种新的自监督表征学习方法,通过结合有区分度的自监督特征和三维理解,以及弱几何球面先验,来提取具有挑战性的图像特征。该方法在训练过程中注入了信息丰富的几何先验,能够更好地考虑重复部分和对称性误差。实验结果表明,该方法在区分对称视图和重复部分方面表现出色,并且能够推广到未见类别的数据集上。
完成下面两步后,将自动完成登录并继续当前操作。