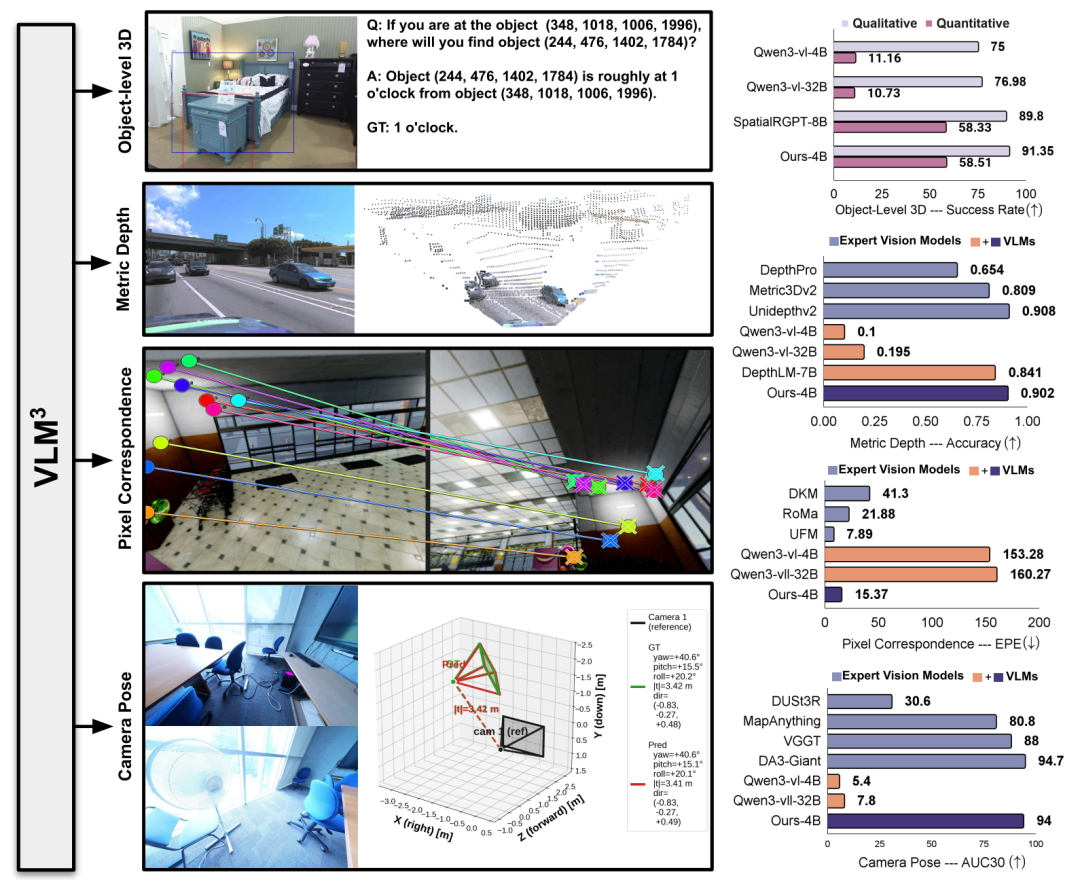
三维空间感知是自动驾驶和机器人领域的核心能力,旨在从二维图像恢复真实世界的空间结构。Meta与普林斯顿大学提出的VLM³框架,基于标准视觉语言模型,统一了物体级三维理解和公制深度估计等任务,显著提升了模型在细粒度三维感知中的表现。研究表明,通用视觉语言模型在三维表征能力上超出预期,为三维视觉领域的统一基础模型提供了新依据。
完成下面两步后,将自动完成登录并继续当前操作。